تحلیل آماری با SPSS ( قسمت اول( دکتر احمد زنده دل کارشناسی ارشد روانشناسی و علوم تربیتی پائیز 1931
|
|
|
- Άμωσις Λαμέρας
- 7 χρόνια πριν
- Προβολές:
Transcript
1 تحلیل آماری با SPSS ( قسمت اول( کارشناسی ارشد روانشناسی و علوم تربیتی دکتر احمد زنده دل پائیز 93
2 کلیات و تعاريف آمار علمي است كه در هر دو جنبه نظري و كاربردي از اهميت زيادي برخوردار بوده و به خصوص طي دهههاي اخير توسعه زيادي پيدا كرده است. آمار را ميتوان يكي از علوم واسطه يا يكي از رشتههاي ميان رشته دانست به طوري كه يكي از ابزارهاي عمده شناخت در بسياري از علوم ديگر است. علم آمار نيز مانند علوم ديگر در نتيجه نيازهاي بشر به وجود آمده است و تاريخي طوالني داشته و از دورانهاي گذشته تا كنون رشد و توسعه آن ادامه يافته است. پيدايش اين علم را ميتوان مقارن با بدو تشكيل دولتهاي اوليه دانست. دولتهاي اوليه نياز به آگاهي از جمعيت تحت سلطه ميزان دارائي و ثروت قلمرو حكومت خود و نيز نيروهاي نظامي تحت امر خود داشتهاند و بنابراين به اموري مانند سرشماري اندازهگيري و تحليل توصيفي اطالعات اقدام ميكردهاند. در آن زمان منظور از آمار ارقام و اطالعات مورد نياز دولتها جهت گرفتن ماليات سربازي و ساير امور مربوط به كشورداري و سياست بوده است اما همين اندازهگيريها و شمارشهاي ابتدايي پايه و اساس آمار امروزي را بنيان نهاده است. در قرن گذشته علم آمار همراه با ساير علوم سير صعودي را پيموده و در مواردي پيشتاز بسياري از علوم ديگر بوده است. اغلب علوم از قبيل فيزيك زيستشناسي اقتصاد مديريت علوم بهداشتي و نيز علوم اجتماعي با استفاده از آمار توانستهاند سرعت پيشرفت و توسعه خود را چند برابر كنند. چون روشها و فنوني كه براي تحقيقات علمي ضروري هستند از علم آمار بدست ميآيد. امروزه علم آمار در اكثر شاخههاي علوم مانند كشاورزي اقتصاد و بازرگاني روانشناسي پزشكي و كاربردهاي گوناگوني داشته و كمتر رشتهاي را ميتوان يافت كه بينياز از بكارگيري روشها و فنون آماري باشد. واژه آمار معادل التين statistics است كه اين كلمه نيز از status به معني دولت گرفته شده است. از آمار يك تعريف يكتا و مشخصي ارائه نشده است و از آنجايي كه در اكثر شاخههاي علوم از آمار استفاده شده است لذا در هر شاخهاي از علم بنابر استفادهاي كه از آمار شده است براي آن تعريف يا تعبيري ارائه كردهاند كه تعداد اين تعاريف از دهها 2
3 مورد متجاوز بوده و هيچ كدام از آنها نميتوانند جامعيت اين علم وسيع را بپوشاند. برخي از تعاريف عموميتري كه براي آمار ارائه شده است به شرح زير است. - آمار علمي است كه خواص جامعه را مورد مطالعه قرار ميدهد. - آمار علمي است كه مشخصات جوامع را به صورت كم ي ولي با در نظر گرفتن اوضاع كيفي آنها مورد بررسي قرار ميدهد. - آمار علمي است كه جنبههاي كم ي نمودهاي اجتماعي را در ارتباط با كيفيت آنها با هم مطالعه ميكند. - آمار عبارت است از مجموعهاي از روشها براي طرح آزمايشها بدست آوردن دادهها و سپس تجزيه و تحليل تعبير و استخراج نتايج آنها. در يك جمعبندي كلي آمار را ميتوان به دو معني زير به كار برد: الف( به معني اعداد و ارقام واقعي يا تقريبي در خصوص مسأله يا فعاليتي مانند اموري از قبيل زاد و مرگ ميزان محصوالت كشاورزي ميزان فروش كااليي خاص و. ب( به معني تكنيكها و روشهايي جهت جمعآوري تنظيم تلخيص و تجزيه و تحليل اطالعات عددي دربارة موضوعات مختلف مانند بررسي قيمت كااليي خاص در گذشته حال و آينده و رابطه آن با برخي ويژگيهاي ديگر مطالعه اثر يك دارو بر روي گروهي بيمار مطالعه اثر يك كود بر ميزان محصوالت كشاورزي و. در يك تقسيمبندي كلي آمار را ميتوان به دو بخش آمار توصيفي و آمار استنباطي )يا آمار تحليلي( تقسيم كرد. آمار توصیفی آمار توصيفي داراي پيشينه بسيار دراز بوده و موضوع آن كم ي كردن ويژگي يا ويژگيهاي يك جامعه و سپس استخراج اطالعات مورد نياز از بين اين كميتها است. آمار توصيفي جزء كوچكي از علم آمار امروزي را تشكيل داده اما عمر آن بسيار طوالني بوده و هنوز نيز داراي كاربردهاي زيادي است. موضوع آمار توصيفي مطالعه كم ي جوامع است. بدين منظور ابتدا ويژگي 3
4 يا ويژگيهاي يك جامعة آماري كم ي شده و سپس اطالعات مورد نياز از بين اين كميتها استخراج ميشود. كميتهاي مورد بحث را دادهها يا دادههاي خام گويند چون اين دادهها محتوي اطالعاتي درباره جامعة مورد نظر هستند كه اين اطالعات به صورت يك پتانسيل در درون دادهها نهفته بوده و لذا به راحتي قابل استفاده نيست. براي استفاده از اطالعات اين دادهها بايد بتوان آنها را به نحو مناسبي پااليش كرد. مراحلي كه در آمار توصيفي براي پااليش دادهها و استخراج اطالعات آنها بر روي آنها انجام ميگيرد به شرح زير است: الف- )جداول آماري( دادهها را در جدول يا جداولي تنظيم ميكنند. چون اين جداول اكثرا برپايه فراوانيها تنظيم ميشود لذا آنها را جدول فراواني يا جدول توزيع فراواني نيز مينامند. اين جداول اطالعات نهفته در دادهها را به صورت خالصه شدهاي در اختيار ميگذارند. ب- )نمودارهاي آماري( از روي جداول بند الف نمودارهايي رسم ميكنند كه آنها را نمودارهاي آماري مينامند. اكثر نمودارهاي آماري چون از روي جداول آماري رسم ميشوند لذا همان اطالعات جداول را در اختيار ميگذارند كه چون اين اطالعات را به صورت تصويري در اختيار ميگذارند لذا استفاده از آنها راحتتر است. بنابراين نمودارهاي آماري را ميتوان بيان هندسي جداول آماري دانست. ج- )تلخيص دادهها( دادهها را در يك يا چند عدد خالصه ميكنند به طوري كه اين اعداد اطالعاتي دربارة كل دادهها را شامل است. اين بخش را تلخيص دادهها مينامند. اعدادي كه اطالعاتي دربارة تمركز دادهها را در اختيار ميگذارند شاخصهاي تمركز يا معيارهاي مركزي گفته اعدادي كه اطالعاتي دربارة پراكندگي دادهها در اختيار ميگذارند را شاخصهاي پراكندگي و اعدادي كه اطالعاتي دربارة چگونگي توزيع دادهها را در اختيار ميگذارند شاخصهاي توزيع مينامند. بنابراين موضوع آمار توصيفي خود به سه قسمت اصلي جداول آماري نمودارهاي آماري و تلخيص دادهها تقسيم ميشود. 4
5 آمار استنباطی آمار استنباطي كه آن را آمار تحليلي نيز مينامند برخالف آمار توصيفي عمري كوتاه داشته و موضوع اصلي علم آمار امروزي را تشكيل ميدهد. آمار استنباطي بر پايه تئوري احتمال بنا شده و موضوع آن چگونگي تعميم نتايج حاصل از يك نمونه به جامعه است به طوري كه خطاي حاصل از اين تعميم مينيمم شود. به عبارت ديگر در آمار استنباطي اطالعات از نمونه به دست آمده و به جامعه تعميم داده ميشود لذا همواره ميزاني خطا در اين تعميم دادن وجود دارد. موضوع آمار استنباطي كم كردن )به حداقل رساندن( اين خطا و افزايش اطمينان در تعميم نتايج حاصل از نمونه به جامعه است. همچنين تعيين مدلها و الگوهاي رياضي براي فعاليتهاي مختلف طبيعي و انساني قسمت ديگري از موضوع آمار استنباطي است. آمار استنباطي خود به دو شاخة آمار پارامتري و آمار ناپارامتري تقسيم ميشود. هرگاه توزيع جامعه نرمال باشد مطالعه آن در حوزه آمار پارامتري است و در غير اين صورت مطالعه آن در حوزه آمار ناپارامتري كه آن را آمار آزاد توزيع نيز مينامند ميباشد. جامعه آماري )جمعيت( مجموعهاي از افراد يا اشيايي كه قرار است يك يا چند خصوصيت آنها مورد مطالعه قرار گيرد را جامعه آماري ميگوييم. به عبارت ديگر جامعة آماري مجموعهاي از افراد يا اشيايي است كه حداقل در يك خاصيت با هم مشترك باشند. واحد آماري )فرد آماري( هر عضوي از جامعة آماري را يك واحد آماري يا يك فرد آماري ميگوييم. صفت مشخصه )صفت ثابت( آن خصوصيتي كه در بين همة افراد يك جامعه آماري مشترك است و در واقع وجه تمايز افراد اين جامعه با ساير جوامع است را صفت مشخصه يا صفت ثابت ميگوييم. 5
6 صفت آماري )صفت متغير( آن خصوصيتي كه از هر فرد آماري مورد نظر است و قرار است آن ويژگي مورد مطالعه قرار گيرد را صفت آماري يا صفت متغير ميناميم. در واقع صفت آماري يا صفت متغير از هر فردي به فرد ديگر تغيير ميكند. صفات متغير بر دو نوعاند صفت كم ي و صفت كيفي. صفت كم ي صفاتي كه به طور مستقيم قابل سنجش و اندازهگيري باشند را صفت كم ي گوييم. مانند سن افراد اندازه قد درآمد تعداد فرزندان خانوار و مانند اينها. صفت كيفي صفتي كه به طور مستقيم قابل سنجش و اندازهگيري نباشند را صفت كيفي گوييم. مانند جنسيت نوع شغل رنگ چشم مزه و مانند اينها. مثال : فرض كنيد در يك شهرستان بخواهيم متوسط درآمد ماهانه خانوارهاي آن شهر را به دستت آوريتم. يعنتي متيختواهيم مطالعهاي بر روي درآمد ماهانه خانوارهاي آن شهر انجام دهيم. در اين صورت مجموعه تمام خانوارهتاي آن شهرستتان جامعتة آماري را تشكيل ميدهد. هر خانواري در آن شهرستان يك واحد آماري يا يك فرد آماري ميباشتد. ختانوار بتودن و ستاكن آن شهرستان بودن صفت مشخصه را تشكيل ميدهد. چون ميخواهيم درآمد ماهانه را مورد مطالعه قرار دهيم لذا درآمد ماهانه هتر خانوار صفت آماري يا صفت متغير را تشكيل ميدهد كه اين صفت يك صفت كم ي است. اما در همين مثال اگر بختواهيم نظتر خانوارهاي اين شهرستان را راجع به يك رويداد اجتماعي )مثال چگونگي شركت آنها در انتخابات شوراي شهر( جويتا شتويم در اين صورت صفت متغير نظر خانواده در مورد موضوع مورد بحث بوده كه اين صتفت كيفتي استت و معمتوال آن را بته صتورت گزينههاي جدا از هم مانند شركت نميكنم شايد شركت كنم حتما شركت خواهم كرد اندازهگيري ميكنند. 6
7 مقیاس سازی از آنجايي كه تحليلهاي آماري بر روي اعداد و ارقام انجام ميگيرد لذا هر صفت آماري را بايد بتوان به نحو مناسبي به عدد تبديل كرد. مثال در يك تحقيق اجتماعي بر روي گروهي از دانشجويان فرض كنيد بخواهيم وزن قد معدل رنگ چشم شهرستان محل سكونت و نظر آنها را راجع به يك مسأله اجتماعي مورد مطالعه قرار دهيم. در اين صورت وزن قد و معدل هر دانشجو چون صفات كم ي هستند به راحتي به عدد تبديل ميشوند. معدل دانشجو به صورت يك نمره ثبت شده موجود است. براي اندازهگيري قد و وزن هر دانشجو نيز وسيله اندازهگيري مناسب و نيز واحد اندازهگيري خاصي وجود دارد كه توسط آنها ميتوان قد و وزن را نيز كم ي كرد. اما وسيله اندازهگيري خاص و نيز واحد اندازهگيري مناسبي براي اندازهگيري و به عدد تبديل كردن رنگ چشم شهرستان محل سكونت و نظر آنها راجع به مسأله اجتماعي وجود ندارد. در تحليل آماري بايد بتوان اين گونه صفات را نيز به نحو مناسبي مورد اندازهگيري قرار داد. يا مثال فرض كنيد بخواهيم وزن و ت ردي سيبهاي يك درخت را مورد مطالعه قرار دهيم. در اين صورت براي هر سيب وزن آن را ميتوان توسط يكي از واحدهاي اندازهگيري وزن اندازه گرفت و آن را به عدد تبديل كرد اما براي اندازهگيري ت ردي سيب برخالف وزن آن وسيله اندازهگيري مناسب و واحد اندازهگيري خاصي وجود ندارد. منظور از مقياسسازي اندازهگيري صفت مورد مطالعه و نسبت دادن اعداد بر طبق قواعد معين به اشياء يا افراد ميباشد. به عبارت ديگر اطالق يك عدد به يك فرد را طبق قاعداي مشخص مقياسسازي گفته و قاعده را يك مقياس گوييم. مقياسها به طور كلي به چهار دسته تقسيم ميشوند مقياس اسمي Scale) (Nominal مقياس ترتيبي يا رتبهاي (Ordinal.(Ratio Scale) و مقياس نسبتي يا نسبي (Interval Scale) مقياس فاصلهاي Scale) مقياس اسمي Scale( )Ordinal در اندازهگيري صفات توسط مقياس اسمي به هر فرد آماري يك عدد نسبت داده ميشود كه اين اعداد صرفا جهت شناسايي و جدا كردن آنها ميباشد. مثال به هر مرد عدد و به هر زن عدد 2 را نسبت ميدهيم. اين اعداد جامعه را به دو طبقه تقسيم ميكند. از اين مقياس عموما در اندازهگيري صفات كيفي كه فاقد شدت و ضعف بوده و شامل اسامي نشانها يا طبقات و گروهها هستند استفاده ميشود. مثال صفاتي مانند رنگ چشم جنسيت مليت گروه خوني و مانند اينها توسط مقياس 7
8 اسمي اندازهگيري ميشوند. اعداد حاصل از مقياس اسمي صرفا بيانگر يك اسم بوده و بر روي آنها چهار عمل اصلي را نميتوان انجام داد. همچنين از اين اعداد جهت مقايسه آنها با يكديگر نيز نميتوان استفاده كرد. مثال در يك مطالعه بر روي شهرستان محل سكونت گروهي از دانشجويان محل سكونت آنها را توسط اعداد 2 n ك د گذاري ميكنيم. مثال فرد مشهدي را با كد فرد اصفهاني را با كد 2 فرد تهراني را با كد 3 و الي آخر تعيين ميكنيم. در اين صورت دادهها شامل مجموعهاي از اعداد 2 n ميباشد. اما اين اعداد صرفا بيانگر اسم يك شهرستان بوده و چهار عمل اصلي را نميتوان روي آنها انجام داد. عبارت 2 در اين دادهها كامال بيمعني است. همچنين از اين اعداد براي مقايسه با يكديگر نيز نميتوان استفاده كرد. در اين جا فردي كه اندازه صفت او 2 ميباشد به معني بيشتر بودن مقدار صفتش از فردي كه اندازه صفت او ميباشد نيست. مقياس ترتيبي )رتبهاي( ( Scale )Ordinal در اندازهگيري صفات توسط مقياس ترتيبي به هر فرد آماري يك عدد نسبت داده ميشود كه اين اعداد عالوه بر شناسايي افراد قابل مقايسه با يكديگر نيز هستند. يعني از اين اعداد براي مقايسه عناصر از نظر كوچكتر يا بزرگتر يا برابر بودن نيز ميتوان استفاده كرد. بنابراين اين اعداد نيز افراد جامعه را طبقهبندي ميكند به نحوي كه اين طبقات داراي ترتيب هستند. اما بر روي اين اعداد نيز چهار عمل اصلي را نميتوان انجام داد. از اين مقياس اكثرا در اندازهگيري صفات كيفي كه داراي شدت و ضعف هستند استفاده ميشود. صفاتي كه توسط مقياس ترتيبي اندازهگيري ميشوند نيز مانند مقياس اسمي شامل اسامي نشانها و طبقات ميباشند با اين تفاوت كه اين صفات داراي شدت و ضعف هستند يعني طبقات يا گروهها رتبهبندي شدهاند. مثال ميزان تحصيالت در افراد يك جامعه كه به طبقات «عالي متوسطه سيكل ششم ابتدايي بيسواد«تقسيمبندي شده است كيفيت يك محصول كه به طبقات «عالي خوب متوسط ضعيف«تقسيمبندي شده است توسط مقياس ترتيبي اندازهگيري ميشوند. مثال فرض كنيد كارگران يك كارخانه را بر حسب ميزان مهارتشان به چهار گروه ضعيف متوسط خوب و عالي طبقهبندي كرده و هر يك از اين گروهها را به ترتيب با كدهاي 3 2 و 4 اندازهگيري كنيم. يعني اگر كارگري داراي مهارت عالي بود اندازه او 4 ميباشد. در اين صورت اين اعداد قابل مقايسه با يكديگر هستند چون كارگري كه اندازه او 2 ميباشد ماهرتر از كارگري است 8
9 كه اندازه او نميدهد. است اما اين به آن معني نيست كه مهارت او دو برابر مهارت كارگر دومي است. ضمنا در اين دادهها 2 معني مقياس فاصلهاي ( Scale )Distance در اندازهگيري صفات توسط مقياس فاصلهاي به هر فرد آماري يك عدد نسبت داده ميشود كه اين اعداد عالوه بر شناسايي و مقايسه آنها از نظر ترتيب )بيشتر يا كمتر بودن( قابل مقايسه بر حسب طول فاصلهها نيز هستند )چقدر بيشتر يا چقدر كمتر(. مقياس فاصلهاي از مفهوم واحد فاصله استفاده ميكند و بدين جهت ميتواند فاصله بين دو عدد را نيز اندازهگيري كند. در مقياس ترتيبي اگر اندازه فرد A 2 و اندازه فرد B بود در اين صورت فقط ميتوانستيم بگوييم كه اندازه صفت فرد بيشتر از اندازه صفت فرد B است. اما در همين مثال اگر اعداد از مقياس فاصلهاي باشند در اين صورت ميتوانيم بگوييم A اندازه صفت فرد A به اندازه يك واحد بيشتر از فرد B است. در دادههاي فاصلهاي عالوه بر انجام مقايسه )مقايسه به صورت ترتيبي و فاصلهاي( عمل جمع و تفريق نيز ميتوان انجام داد. از اين مقياس اكثرا در اندازهگيري صفات كمي استفاده ميشود و اندازهگيري نيز به نحوي است كه در آن عدد صفر جنبه مطلق نداشته بلكه قراردادي است. به عبارت ديگر در مقياس فاصلهاي نقطهاي را به عنوان مبداء قرارداد كرده و آن را با صفر نشان ميدهند و سپس توسط يك واحد اندازهگيري خاص و به فواصل مساوي در طرفين مبداء صفت آماري را اندازهگيري ميكنند. بهترين مثالي كه در اين خصوص ميتوان زد اندازهگيري ميزان دما توسط درجه سانتيگراد است. در اندازهگيري دما توسط سانتيگراد قرارداد شده است كه دمايي كه در آن آب شروع به يخ زدن ميكند را به عنوان مبداء در نظر گرفته و با صفر نشان ميدهند و دمايي كه در آن آب شروع به جوشيدن ميكند را با نشان ميدهند. سپس اين فاصله را به قسمت مساوي تقسيم كرده و هر قسمت را يك درجه سانتيگراد گويند. لذا عدد صفر جنبه مطلق نداشته بلكه قراردادي است. به عبارت ديگر اگر دماي جسمي درجه سانتيگراد باشد به اين معني نيست كه اين جسم هيچگونه دمايي ندارد. به طور خالصه از مقياس فاصلهاي در اندازهگيري صفات كمي استفاده ميشود و نحوه اندازهگيري به گونهاي است كه: الف( در اين دادهها صفر جنبة مطلق نداشته بلكه قراردادي است. 9
10 ب( اين دادهها قابل مقايسه و جمع جبري با يكديگر بوده اما نسبت در اين دادهها بيمعني است. مثال اگر اندازه يك فرد 4 و فرد ديگر 2 باشد در اين صورت 4 2 و 4 2 معنيدار است اما عبارت 2 بيمعني است. يعني نميتوان گفت فردي 4 2 كه داراي اندازه صفت 4 است ميزان صفتش دو برابر فردي است كه اندازه صفت او 2 است. ج( در اين دادهها نسبت فواصل با تغيير واحد اندازهگيري تغيير نميكند. مثال 2 فرض كنيد درجه حرارت چهار جسم خاص بر حسب سانتيگراد عبارت باشد از 5 و. 3 درجه حرارت همين چهار جسم بر حسب فارانهايت و طبق رابطة 5 به ترتيب برابر است با 32 y 9 x و 86. حال موارد زير را در نظر ميگيريم: الف( جسمي كه درجه حرارت آن بر حسب سانتيگراد ميباشد به اين معني نيست كه فاقد حرارت است چون درجه حرارت همين جسم بر حسب فارنهايت 32 ميباشد. پس صفر در اين جا صرفا قراردادي است. ب( اگر دو درجه حرارت 3 و درجه سانتيگراد را با يكديگر جمع يا تفريق كنيم درجه حرارت به ترتيب 4 و يا 2 سانتيگراد به دست ميآيد كه اين اعداد معنيدار هستند. ج( نسبت درجه حرارت جسمي كه بر حسب سانتيگراد حرارتش 3 ميباشد به جسمي كه داراي درجه سانتيگراد است است اما اين به آن معني نيست كه حرارت اين جسم 3 برابر جسم ديگر است. چون نسبت درجه حرارت همين دو جسم بر حسب فارانهايت 72 ميباشد. اگر دماي جسم دوم واقعا سه برابر دماي جسم اول بود اين دما را با هر / واحدي كه اندازهگيري كنيم نسبت 3 بايد ثابت باشد در صورتي كه ديديم چنين نيست. پس اعداد 3 و / 72 در اين مورد بيمعني هستند يعني بر روي اين دادهها نسبت تعريف نميشود. 0
11 با كمي د( دقت مشاهده ميشود كه نسبت فواصل هر دو عدد در هر دو واحد اندازهگيري ثابت است مثال توجه توجه كنيد كه اگر درجه حرارت را بر حسب واحد كلوين كه داراي صفر مطلق است اندازهگيري كنيم آنگاه مقياس اندازهگيري فاصلهاي نبوده بلكه مقياس نسبتي است كه در قسمت بعد بحث ميشود. مقياس نسبتي )مقياس نسبي( ( Scale )Ratio در اندازهگيري صفات توسط مقياس نسبتي كه آن را مقياس نسبي نيز مينامند به هر فرد آماري يك عدد نسبت داده ميشود كه اين اعداد عالوه بر شناسايي و مقايسه آنها از نظر ترتيب )بيشتر يا كمتر يا برابر بودن( و نيز قابل مقايسه بر حسب طول فاصلهها )چقدر بيشتر يا چقدر كمتر( قابل مقايسه از نظر نسبت )چند برابر بزرگتر يا كوچكتر( نيز هستند. در مقياس ترتيبي اگر اندازه فرد A 2 و اندازه فرد B بود در اين صورت فقط ميتوانستيم بگوييم كه اندازه صفت بيشتر از اندازه صفت فرد B است. اما اگر اعداد از مقياس فاصلهاي باشند در اين صورت ميتوانيم بگوييم اندازه صفت فرد A به اندازه يك واحد بيشتر از فرد B است. حال اگر اعداد از مقياس نسبتي باشند عالوه بر اين كه ميتوان گفت فرد A به فرد A اندازه يك واحد بيشتر از فرد B نسبت نيز تعريف ميشود. است ميتوان گفت كه اندازه صفت A 2 برابر اندازه صفت فرد B است يعني روي اين دادهها در دادههاي نسبتي عالوه بر انجام مقايسه )مقايسه به صورت ترتيبي و فاصلهاي( و نيز عمل جمع و تفريق اعمال ضرب و تقسيم نيز تعريف ميشود. اين مقياس كه عاليترين نوع مقياس ميباشد در اندازهگيري صفات كم ي استفاده ميشود و اندازهگيري نيز به نحوي است كه در آن عدد صفر جنبه مطلق دارد. صفاتي مانند وزن طول سطح حجم و مانند اينها. در اين مقياس عدد صفر به معني نقطه شروع بوده و جنبه مطلق دارد. مثال اگر طول جسم A سانتيمتر و طول جسم 5 B سانتيمتر باشد آن گاه طول جسم حاصل از رديف كردن A و 5 B سانتيمتر ميباشد. همچنين ميتوان ادعا كرد كه طول جسم A 2 برابر طول جسم
12 است. در صورتي كه اگر درجه حرارت جسم A درجه سانتيگراد و درجه حرارت جسم 5 B درجه سانتيگراد باشد B نميتوان ادعا كرد كه درجه حرارت جسم A دو برابر درجه حرارت جسم B است. توجه 2 نوع مقياس اندازهگيري تنها به صفت آماري بستگي نداشته بلكه به چگونگي اندازهگيري نيز بستگي دارد. مثال فرض كنيد بخواهيم اندازه قد دانشجويان يك كالس را اندازهگيري كنيم. اگر دانشجويان يك كالس را از لحاظ اندازه قد به گروههاي كوتاه قد قد متوسط و بلند قد تقسيم كنيم از مقياس ترتيبي استفاده كردهايم. اگر اندازه قد دانشجويان را بر حسب اندازه قد يكي از دانشجويان اندازهگيري كنيم مثال افرادي كه هم قد او هستند اندازه قد آنها صفر افرادي كه قدشان بلندتر از اوست بر حسب ميزان بلندي بر حسب سانتيمتر عدد بدهيم مثال 2 سانتيمتر سانتيمتر و و افرادي كه قدشان كوتاهتر از اوست بر حسب ميزان كوتاهي بر حسب سانتيمتر عدد بدهيم مثال - سانتيمتر 2- سانتيمتر و غيره. در اين صورت از مقياس فاصلهاي استفاده كردهايم. اما اگر اندازه قد افراد را به صورت متريك و با يكي از واحدهاي اندازهگيري مانند سانتيمتر اندازهگيري كنيم )چيزي كه مرسوم است( در اين صورت از مقياس نسبتي استفاده كردهايم. به عنوان مثال ديگر مي توان از اندازه گيري دما بر حسب درجه سانتي گراد و درجه كلوين نام برد كه در اندازه گيري دما بر حسب سانتي گراد همانطوريكه بحث شد مقياس اندازه گيري فاصله اي اما در اندازه گيري توسط كلوين مقياس نسبتي است. و نيز اگر دما را به صورت سرد معتدل گرم اندازه گيري كنيم در اينصورت مقياس ترتيبي است. توجه 9 يك رابطه ترتيبي بين مقياسهاي اندازه گيري برقرار است. بدين ترتيب كه مقياس اسمي پست ترين مقياس مقياس ترتيبي همان مقياس اسمي است با يك خاصيت اضافه تر مقياس فاصله اي همان مقياس ترتيبي است با يك خاصيت اضافه تر و خالصه مقياس نسبتي كه عالي ترين مقياس اندازه گيري است همان مقياس فاصله اي است با يك خاصيت اضافه تر. 2
13 توجه 4: مقياس جمع پذیر یا مقياس ليکرت ( Scale ) Summative نوع ديگري از مقياس اندازه گيري كه با نام مقياس جمع پذير و اكثرا با نام مقياس ليكرت از آن ياد مي شود سطحي از اندازه گيري است كه در آن يك صفت به صورت ترتيبي اندازه گيري مي شود با اين تفاوت كه فاصله بين گزينه هاي مختلف يكسان در نظر گرفته مي شود. به عبارت ديگر در سطح اندازه گيري ترتيبي يك صفت به نحوي به عدد تبديل مي شود كه اين اعداد عالوه بر شناسائي افراد داراي يك رابطه ترتيبي نيز هستند اما فاصله بين اين مقادير لزوما يكسان نيست. مثال اگر كيفيت يك محصول را به صورت " ضعيف متوسط خوب عالي" اندازه گيري كنيم از سطح اندازه گيري ترتيبي استفاده كرده ايم. در اين حالت اختالف كيفيت دو محصول كه به صورت " ضعيف" و " متوسط" اندازه گيري شده است لزوما برابر با اختالف كيفيت دو محصول كه به صورت " متوسط" و " خوب" اندازه گيري شده است نيست. اما اگر اين اختالفها يكسان باشد آنگاه مي توان اين سطح از اندازه گيري را جمع پذير يا ليكرت دانست. بر اين اساس مقياس ليكرت در واقع بين دو مقياس ترتيبي و فاصله اي قرار مي گيرد. از اين مقياس اكثرا در اندازه گيري صفات كيفي كه مقادير آن داراي شدت و ضعف است و يا صفاتي كه ذاتا كمي بوده اما قادر به اندازه گيري كمي آنها نيستيم استفاده مي شود و بخصوص از اين مقياس در طراحي پرسشنامه ها و گزينه هاي سئواالت يك پرسشنامه استفاده مي شود. مثال فرض كنيد بخواهيد توسط يك سئوال در پرسشنامه ميزان رضايت پاسخگو از كيفيت يك محصول را اندازه گيري كنيد. و فرض كنيد سئوال را به " صورت شما تا چه حد از كيفيت اين محصول رضايت داريد" قرار داده باشيد. در اينصورت اگر پاسخ اين سئوال را به صورت گزينه هاي "خيلي كم" "كم" "متوسط" "زياد" "خيلي زياد" قرار داده باشيد از طيف اندازه گيري ليكرت استفاده كرده ايد. در طيف ليكرت اكثرا پاسخهاي سئواالت پرسشنامه ها را در پنج و يا هفت گزينه قرار مي دهند. مثال گزينه هائي مانند "كامال موافقم" "موافقم" "نظري ندارم" "مخالفم" "كامال مخالفم" قرار مي دهند. در طيف ليكرت به گزينه ها به ترتيب كدهاي الي 5 اختصاص مي دهند. تفاوت اصلي بين طيف ليكرت با طيف ترتيبي در آن است كه مي توان متغيرهاي ليكرت را با يكديگر جمع كرد و به همين دليل آن را جمع پذير نيز مي نامند. در طراحي پرسشنامه ها معموال براي اندازه گيري برخي صفات كه داراي جنبه هاي مختلف است تعدادي سئوال در پرسشنامه قرار داده و پاسخها را در طيف ليكرت قرار مي دهند. سپس از جمع بستن پاسخهاي داده شده به اين سئواالت يك اندازه كمي براي آن صفت به دست مي آيد. حاصل جمع چند متغير ليكرت را مي توان يك متغير در سطح اندازه گيري فاصله اي دانست و به همين دليل از روشهاي آماري خيلي بيشتري مي توان استفاده كرد. مثال فرض كنيد توسط سئواالت يك 3
14 پرسشنامه بخواهيم ميزان رضايت شغلي را اندازه گيري كنيم. فرض كنيد رضايت شغلي داراي ابعاد رضايت از حقوق رضايت از همكار رضايت از سرپرست و... باشد. در اينصورت براي هركدام از اين ابعاد يك يا بيش از يك سئوال با پاسخهائي در طيف ليكرت در پرسشنامه قرار مي دهند. حال مي توان از جمع بستن پاسخهاي داده شده به اين سئواالت يك اندازه كمي از ميزان رضايت شغلي پاسخگو به دست آورد. دادهها مجموعه اعداد به دست آمده از اندازهگيري يك صفت آماري با يك مقياس مناسب را دادهها يا data گوييم. دادهها بر دو نوعاند دادههاي گسسته و دادههاي پيوسته. دادههاي گسسته دادههاي حاصل از اندازهگيري با مقياسهاي اسمي و ترتيبي و نيز دادههاي شمارشي را دادههاي گسسته گوييم. به بيان ديگر دادههاي گسسته دادههايي هستند كه در آنها بين هر دو دادة متوالي دادة ديگري از صفت مورد نظر را نتوان قرار داد. مثال اگر تعداد فرزندان خانوارهاي يك محله را ثبت كرده باشيم اين دادهها گسسته هستند چون بين دو دادة 2 و 3 كه دو دادة متوالي هستند هيچ دادة ديگري از تعداد فرزندان را نميتوان قرار داد. به عبارت ديگر هيچ خانواري را نميتوان يافت كه تعداد فرزندان آن عددي بين 2 و 3 )مثال 2( / 5 باشد. دادههاي پيوسته دادههايي كه از راه اندازهگيري با مقياسهاي فاصلهاي و نسبتي به دست ميآيند را دادههاي پيوسته گوييم. به بيان ديگر دادههاي پيوسته دادههايي هستند كه در آنها بين هر دو دادة متوالي دادة ديگري از صفت مورد نظر را بتوان قرار داد. مثال فرض كنيد اندازه قد دانشجويان يك دانشگاه را ثبت كنيم. در اين صورت اين دادهها از نوع پيوستهاند. چون فرض كنيد اندازه قد دو نفر از دانشجويان 65 و سانتيمتر باشد. در اين صورت ميتوان فرد ديگري را يافت كه اندازه قد او بين و 66 سانتيمتر مثال 65 / 5 سانتيمتر باشد. كافي است دقت وسيله اندازهگيري را افزايش داد. در اين صورت هر قدر اين دو 4
15 داده به هم نزديكتر شوند باز هم ميتوان فردي را يافت كه اندازه قدش عددي بين آن دو عدد باشد. دادههاي حاصل از وزن و زمان نيز وقتي به صورت متريك اندازهگيري شوند از نوع پيوسته هستند. متغير از آن جايي كه صفت آماري از فردي به فرد ديگر تغيير ميكند لذا آن را متغير نيز مينامند. متغيرها را به طور كلي به دو دسته متغير گروهي و متغير عددي تقسيم ميكنند. متغير گروهي متغيري كه با مقياس اسمي يا ترتيبي سنجيده شده و بر اساس آن جمعيت گروهبندي ميشود را متغير گروهي مينامند مانند گروه خوني مليت نژاد و مانند اينها. متغير عددي متغيري كه از راه شمارش يا اندازهگيري با مقياسهاي فاصلهاي و نسبتي به دست ميآيد را متغير عددي مينامند مانند تعداد فرزندان وزن و مانند اينها. 5
16 کلیات آمار توصیفی در يك تقسيم بندي كلي روشهاي آماري به دو دسته توصيفي و استنباطي تقسيم مي شوند. موضوع آمار توصيفي كم ي كردن ويژگي يا ويژگيهاي يك جامعه و سپس استخراج اطالعات موردنياز از روي آن كميتها مي باشد. كميتهايي كه آنها را داده ها يا داده هاي خام مي نامند چون اين داده ها محتوي اطالعاتي درباره ويژگي مورد نظر هستند اما اين اطالعات بصورت يك پتانسيل در درون داده ها نهفته است. براي استفاده از اين اطالعات بايد بتوان داده ها را به نحو مناسبي پااليش كرد. مراحلي كه در آمار توصيفي براي پااليش داده ها و استخراج اطالعات مورد نياز بر روي آنها به كار مي برند به شرح زير است. الف: داده ها را در جدول يا جداولي تنظيم ميكنند) جداول آماري(. اين جداول اطالعات نهفته در داده ها را به صورت دسته بندي شده در اختيار مي گذارند و معموال داراي ستونهاي فراواني فراواني نسبي درصد فراواني تجمعي و ستونهاي ديگري كه بنا به نياز به اين جداول اضافه مي شود. ب: از روي جداول آماري نمودارهائي رسم مي كنند )نمودارهاي آماري(. اين نمودارها همان اطالعات جداول را منتها به صورت تصويري در اختيار مي گذارند و لذا استفاده از آنها راحتتر است. نمودارهاي آماري خيلي زياد و متنوع بوده و بنا بر نوع داده ها و اطالعات مورد نياز اين نمودارها متفاوت است. ج: داده ها را در يك يا چند عدد خالصه مي كنند)تلخيص داده ها(. بطوريكه اين اعداد يك اطالعات كلي در مورد همه داده ها را شامل باشد. اعدادي كه اطالعاتي در مورد تمركز داده ها را شامل است شاخصهاي تمركز اعدادي كه اطالعاتي در مورد پراكندگي داده ها را شامل است شاخصهاي پراكندگي و اعدادي كه اطالعاتي در مورد چگونگي توزيع داده ها را شامل است شاخصهاي توزيع مي نامند. 6
17 شاخصهاي تمركز: شاخصهاي تمركز اعدادي هستند كه اطالعاتي در باره تمركز داده ها در اختيار مي گذارند و عمده ترين آنها شامل ميانگين ( حسابي وزني هندسي هارمونيك و... ( ميانه و نما )مد( مي باشد. ميانگين عمده ترين و پركاربردترين اين شاخصها بوده و داراي انواع مختلف است. ميانگين در واقع مركز ثقل داد ها است يعني نقطه اي است كه وزن داده ها در سمت چپ و راست آن با هم برابر است. يا به عبارت ديگر مجموع انحرافات داده ها در سمت چپ و راست ميانگين با هم برابر است. ميانه نقطه وسط داده ها است. يعني داده اي كه تعداد داده هاي سمت چپ و راست آن با هم برابر است. مد يا نما داده اي است كه بيشترين فراواني را دارد. از بين اين شاخصها ميانگين داراي ارزش بيشتري بوده و به همين جهت پر كاربرد تر از ميانه و نما است. اما با اين حال هنگامي كه داده ها از يك صفت كيفي و در سطح اندازه گيري ترتيبي هستند از ميانه به عنوان شاخص تمركز استفاده مي شود. مد يا نما ارزش خيلي كمتري نسبت به ميانگين و ميانه داشته و در نمونه هاي كوچك فاقد اعتبار است. اما با اين حال هنگامي كه داده ها از يك صفت كيفي و در سطح اندازه گيري ترتيبي هستند ناچارا از مد به عنوان شاخص تمركز استفاده مي شود. مثال شاخص تمركز مناسب براي قدف وزن نمرات و ويژگي هائي از اين قبيل ميانگين است. شاخص تمركز مناسب براي ديدگاه دانشجويان نسبت به كيفيت برگزاري كالس درس آمار كه به صورت رتبه اي خيلي كم كم متوسط خوب خيلي خوب اندازه گيري شده است ميانه و شاخص تمركز مناسب براي گروه خوني دانشجويان مد است. شاخصهاي پراكندگي: شاخصهاي پراكندگي اعدادي هستند كه اطالعاتي در باره پراكندگي داده ها در اختيار مي گذارند و عمده ترين آنها واريانس و انحراف معيار است. واريانس در واقع ميانگين مجذور تفاضل داد ها از ميانگينشان است و شاخص خوبي براي اندازه گيري پراكندگي است منتها ايراد واريانس در آن است كه واحد اندازه گيري آن با واحد اندازه گيري داده ها يكسان نبوده بلكه مجذور يا مربع واحد اندازه گيري داده ها است. مثال اگر داده ها همه بر حسب متر باشد آنگاه ميانگين آنها نيز بر حسب متر خواهد بود حال آنكه واريانس آنها بر حسب متر مربع خواهد بود. به همين دليل و به جهت يكسان سازي واحد اندازه گيري اين شاخص با 7
18 واحد اندازه گيري داده ها از واريانس جذر گرفته و جذر آن را انحراف معيار يا انحراف استاندارد ناميدند كه واحد اندازه گيري انحراف معيار با واحد اندازه گيري داده ها يكسان است. شاخصهاي توزیع: شاخصهاي توزيع اعدادي هستند كه اطالعاتي در باره توزيع داده ها در اختيار مي گذارند و اين شاخصها شامل چولگي و كشيدگي است. چولگي شاخصي است براي اندازه گيري ميزان عدم تقارن يا كجي يك توزيع نسبت به توزيع نرمال. كشيدگي نيز شاخصي است براي اندازه گيري ميزان پراكندگي نسبت به توزيع نرمال. راجع به چولگي و كشيدگي بعدا و در بخش SPSS به طور مفصل بحث خواهد شد. به جهت اهميت نحوه محاسبه ميانگين و واريانس با ذكر مثال در زير خواهد آمد. محاسبه ميانگين و واریانس) جامعه( : N دادههاي يك جامعة x x 2 x فرض كنيد N نفره باشد. ميانگين و واريانس اين جامعه كه آنها را به ترتيب با و نشان ميدهيم به صورت زير به دست ميآيد. ( ) 8
19 حال اگر اين داده ها يك نمونه از يك جامعه باشد فرمول محاسبه واريانس آن كمي متفاوت است. به عبارت ديگر فرض كنيد x n x 2 x يك نمونه تصادفي n نشان مي دهيم به صورت زير تعريف مي شود. تائي از يك جامعه باشد. در اينصورت ميانگين و واريانس نمونه كه آنها را به ترتيب با و ( ) مثال 9: فرض كنيد 2 مقادير يك جامعه محدود پنج نفره باشد. ميانگين و واريانس اين جامعه را به دست آوريد. واريانس را از هر دو فرمول آن به دست آوريد. حل: داريم: واريانس ( فرمول اول(: σ 9
20 واريانس ( فرمول دوم(: مثال 4: فرض كنيد مقادير يك نمونه تصادفي از يك جامعه باشد. ميانگين و واريانس اين نمونه را به دست آوريد. واريانس نمونه را از هر دو فرمول آن به دست آوريد. حل: داريم: واريانس نمونه) فرمول اول(: واريانس نمونه ( فرمول دوم(: 20
21 کلیات آمار استنباطی موضوع آمار استنباطي كه آنرا آمار تحليلي نيز مي نامند و قسمت عمده علم آمار امروزي را تشكيل مي دهد مطالعة يك جامعه از روي داده هاي يك نمونه تصادفي از آن جامعه است يعني در آمار استنباطي فرض براين است كه به داليل مختلف امكان مشاهدة جامعة آماري نبود و بلكه تنها مي توان يك نمونه تصادفي از آن جامعه را در دسترس داشت. لذا هر گونه استنباط و استنتاج دربارة جامعه بايد از طريق داده هاي آن نمونه انجام گيرد. واضح است كه تعميم نتايج حاصل از يك نمونه به كل جامعه توام با ميزاني خطاست و لذا قسمت عمده اي از موضوع آمار استنباطي استفاده از روشهاي رياضي در به حداقل رساندن اين خطا است و البته قسمت ديگري از موضوع آمار استنباطي كه بخصوص طي سالهاي اخير بسيار مورد توجه واقع شده است بحث مدل سازي است يعني استفاده از مدلها و الگوهاي رياضي در تعيين رابطة بين متغيرهاي انساني و )طبيعي( است. يعني در آمار استنباطي فرض بر اين است كه به دالئل مختلف كه اين دالئل به خصوص در بحث آمار اقتصادي اجتماعي بحث هزينه و زمان است جامعه سرشماري نمي شود بلكه از جامعه يك نمونه انتخاب مي شود. منظور از سرشماري نيز مورد مطالعه قرار دادن كل افراد جامعه است. يعني در يك مطالعه آماري هر گاه همه افراد جامعه مورد مطالعه قرار گيرند آن را سرشماري گويند. بنابراين در بحث آمار استنباطي اولين گام چگونگي نمونه گيري از يك جامعه است.واضح است كه از يك جامعه به روشهاي مختلف مي توان نمونه گرفت اما در آمار اين نمونه بايد طوري باشد كه بتواند به خوبي معرف جامعه اش باشد كه چنين نمونه اي را نمونة ناريب مي نامند. نمونه تصادفي نمونه اي نااریب است بنابراين روش نمونه گيري در آمار بايد بطور تصادفي باشد و منظور از نمونه تصادفي نمونه اي است كه در آن هر فرد جامعه شانسي براي انتخاب در نمونه را داشته و اين شانس براي همه افراد جامعه يكسان باشد. براي نمونه گيري تصادفي از يك جامعه بنابر چگونگي توزيع آن جامعه و موضوع تحت مطالعه روشهاي مختلفي ارائه شده است كه عمده ترين روشهاي كالسيك نمونه گيري شامل موارد زير است: نمونه گيري تصادفي ساده نمونه گيري تصادفي منظم )سيستماتيك( نمونه گيري تصادفي طبقه اي نمونه گيري تصادفي خوشه اي
22 نمونه گيري تصادفي ساده: نمونه گيري تصادفي ساده پايه و اساس همه روشهاي نمونه گيري آماري است. در اين روش نمونه به نحوي انتخاب مي شود كه همه افراد جامعه شانسي براي انتخاب در نمونه را داشته و اين شانس براي همه افراد يكسان باشد. نمونه گيري تصادفي ساده را مي توان به دو روش با جايگذاري و بدون جايگذاري انجام داد. در روش با جايگذاري هر فرد جامعه مي تواند بيش از يكبار در نمونه انتخاب شود حال آنكه در روش بدون جايگذاري هر فرد جامعه فقط يكبار شانسي براي انتخاب در نمونه را دارد. نمونه گيري تصادفي منظم )سيستماتيک(: از اين روش هنگامي استفاده مي شود كه ليستي از افراد جامعه در دسترس باشد. در اين روش ابتدا گامي از قبل تعيين ميشود و گام يك عدد صحيح مثبت مانند k است كه معموال آن را از رابطه k=n/n به دست مي آورند كه در آن N حجم جامعه و n حجم نمونه است. سپس از بين اعداد صحيح تا k يك عدد به تصادف انتخاب مي شود. فرد متناظر با عدد انتخاب شده اولين عضو نمونه است و ساير اعضاي نمونه به تعداد گام مورد نظر به نمونه اضافه مي شوند. بنابر اين در اين روش اولين عضو نمونه بطور تصادفي انتخاب شده و ساير اعضاي نمونه وابسته به نفر اول به نمونه وارد مي شوند. مثال فرض كنيد بخواهيم از يك جامعه 000=N نفره يك نمونه 00=n تائي به روش سيستماتيك انتخاب كنيم و نيز فرض كنيد ليستي از افراد جامعه در دسترس باشد. در اين صورت ابتدا گام حركت را به صورت k=n/n=000/00=0 تعيين مي كنيم. سپس از بين اعداد صحيح تا 0 يك عدد به تصادف انتخاب مي كنيم. فرض كنيد عدد انتخاب شده 4 باشد در اين صورت فرد رديف چهارم در 24+0=34 ليست افراد جامعه اولين عضو نمونه است. ساير اعضاي نمونه افراد رديفهاي 4=4+0 = =994 هستند. نمونه گيري طبقه اي: از اين روش هنگامي استفاده مي شود كه افراد جامعه به گروههاي مجزا از يكديگر افراز شده باشند و اين گروه بندي به نحوي باشد كه افرادي كه داخل هر گروه قرار مي گيرند متجانس اما گروههاي مختلف نا متناجس باشند. به عبارت ديگر واريانس يا 22
23 پراكندگي در داخل هر گروه كم اما بين گروهها زياد باشد. چنين گروههائي را طبقه گويند. در روش طبقه اي نمونه به نحوي انتخاب مي شود كه از هر طبقه اي به نسبت حجم آن طبقه تعدادي در نمونه داشته باشيم. مثال فرض كنيد بخواهيم توسط نمونه گيري از يك شهر بزرگ درآمد ماهانه خانوارهاي آن شهر را برآورد كنيم و نيز فرض كنيد خانوارهاي اين شهر را بتوان از لحاظ درآمد به گروههاي كم درآمد درآمد متوسط درآمد باال و درآمد خيلي باال تقسيم كرد. در اين صورت هر كدام از اين گروههاي درآمدي يك طبقه را تشكيل مي دهند چون خانوارهائي كه در اين گروهها قرار ميگيرند از لحاظ درآمدي شبيه به يكديگر بوده اما خانوارهاي گروههاي مختلف از لحاظ درآمدي متفاوت از يكديگر هستند. به عبارت ديگر واريانس يا پراكندگي درآمد در بين خانوارهاي هر كدام از اين گروهها كم اما بين گروهها زياد است. بنابر اين اين گروهها را طبقه گفته و براي نمونه گيري از روش نمونه گيري طبقه اي استفاده مي كنيم. به اين ترتيب كه از همه اين گروههاي درآمدي يا همان طبقات نمونه ميگيريم اما از هر طبقه اي به نسبت حجم آن طبقه. مثال اگر طبقه افراد با درآمد پايين 20 درصد از افراد جامعه را تشكيل مي دهند در اين صورت 20 درصد از حجم نمونه را به اين طبقه اختصاص مي دهيم و به همين ترتيب الي آخر. نمونه گيري خوشه اي: از اين روش نيز هنگامي استفاده مي كنيم كه افراد جامعه به گروههاي مجزا از يكديگر افراز شده باشند با اين تفاوت كه در اين حالت گروه بندي به نحوي است كه افرادي كه داخل هر گروه قرار مي گيرند نامتجانس اما گروههاي مختلف متجانس هستند. به عبارت ديگر واريانس يا پراكندگي در داخل هر گروه زياد اما بين گروهها كم است. يعني در واقع هر كدام از اين گروهها را مي توان نمونه كوچك شده اي از كل جامعه در نظر گرفت كه همه خواص جامعه را شامل است. چنين گروههائي را خوشه مي ناميم. در نمونه گيري خوشه اي تعدادي از خوشه ها به تصادف انتخاب شده و آنها را سرشماري مي كنند. و يا در صورت بزرگ بودن خوشه ها پس از انتخاب خوشه هاي نمونه از آنها يك نمونه تصادفي انتخاب مي شود) خوشه اي دو مرحله اي( و يا ممكن است پس از انتخاب خوشه هاي نمونه از هر كدام از اين خوشه ها نمونه به روش طبقه اي انتخاب كرد و يا حتي مجددا خوشه هاي نمونه را خوشه بندي كرده و از آنها به روش خوشه اي نمونه گرفت)خوشه اي چند مرحله اي(. در هر صورت در روش خوشه اي از همه خوشه هاي جامعه نمونه گرفته نمي شود بلكه تنها از تعدادي از آنها نمونه گرفته مي شود. مثال فرض كنيد بخواهيم در يك تحقيق ديدگاه دانشجويان يك دانشگاه بزرگ را در باره يك رويداد اجتماعي جويا شويم. فرض كنيد اين 23
24 دانشگاه داراي چند دانشكده بوده كه هر دانشكده اي داراي يك ساختمان مجزائي است. از آنجائي كه از نظر موضوع تحت مطالعه تفاوتي بين دانشجويان دانشكده هاي مختلف با يكديگر نيست لذا هر دانشكده اي را مي توان به عنوان يك خوشه در نظر گرفت و بنابر اين براي نمونه گيري از اين دانشگاه نيازي به اينكه از همه اين دانشكده ها نمونه گرفت نيست بلكه كافي است يك يا چند دانشكده را به عنوان خوشه هاي نمونه انتخاب كرد. از آنجائيكه دانشجويان هر دانشكده زياد بوده و امكان سرشماري همه آنها نيست ( امكان اينكه همه دانشجويان را مورد پرسش و يررسي قرار داد( لذا مي توان از هر كدام از دانشكده هاي نمونه يك نمونه تصادفي گرفت. فرض كنيد ساختمان هر دانشكده اي چند طبقه بوده و كالسهاي دانشجويان در طبقات مختلف اين ساختمان باشد. از آنجائيكه از لحاظ موضوع تحت مطالعه تفاوتي بين دانشجويان در طبقات مختلف نيست لذا هر كدام از اين طبقات را مي توان به عنوان يك خوشه در نظر گرفت و بر اين اساس نيازي به اينكه از دانشجويان همه طبقات نمونه گرفت نيست بلكه كافي است يكي از اين طبقات را به عنوان خوشه نمونه در نظر گرفته و دانشجويان آن طبقه را مورد سرشماري قرار داد. يا حتي اگر دانشجويان هر طبقه زياد باشند مي توان از آنها يك نمونه تصادفي انتخاب كرده و تنها آنها را مورد بررسي قرار داد. توجه 4: در مسائل عملي و كاربردي ممکن است از یکي از این روشها و یا از تركيبي از آنها استفاده شود. پارامتر: هر ويژگي عددي يك جامعه را يك پارامتر گويند به عبارت ديگر پارامتر عددي است كه خاصيتي از جامعه را مشخص مي كند. مثال ميانگين و واريانس جامعه 2, پارامتر هستند پارامترها مقادير ثابتي هستند كه در عمل هميشه مجهولند. آماره: )استاتيستيک :)statistic آماره عددي است كه خاصيتي از نمونه را بيان و مشخص مي كند. به عبارت ديگر هر تابعي از نمونه كه به هيچ پارامتر مجهولي بستگي نداشته باشد را آماره گويند. مثال ميانگين و واريانس نمونه 2 s, x آماره هستند. 24
25 برآوردگر)برآورد یاب(: آماره اي است كه از آن براي برآورد يا تخمين پارامتري از جامعه استفاده مي شود. به عبارت ديگر هرگاه از يك آماره براي برآورد يا تخمين پارامتري از جامعه استفاده شود آن آماره را برآورد گر يا تخمين زن آن پارامتر گويند مثال ميانگين و واريانس نمونه برآوردگرهائي براي ميانگين و واريانس جامعه هستند. توجه 5: پارامترها مقادير ثابت و مجهولند اما برآورد گرها و بطور كلي آماره ها ثابت نبوده بلكه متغير تصادفي هستند. نحوة برآورد پارامترها: بطور كلي پارامترها را به دو روش نقطه اي و فاصله اي برآورد مي كنند. در روش نقطه اي پارامتر جامعه را توسط يكي از آماره هاي نمونه برآورد مي كنند. مثال ميانگين نمونه يك برآورد نقطه اي براي ميانگين جامعه است. اما در روش فاصله اي پارامتر جامعه توسط يك فاصله برآورد مي شود. فاصله اي كه با ضريب اطمينان خوبي پارامتر جامعه را در بر بگيرد. 25
26 نرم افزار SPSS SPSS مخفف Statistical Package for Social Science يكي از قديمي ترين برنامه هاي آماري است كه حتي قبل از پيدايش كامپيوتر هاي شخصي نيز اين نرم افزار وجود داشته است و توسط اين برنامه آماري تقريبا همه محاسبات و تحليل ها و آزمون هاي آماري بخصوص رشته هاي غير آماري را به راحتي مي توان انجام داد. پايه اوليه اين نرم افزار در سال 968 توسط سه دانشجوي دكتري در رشته هاي علوم اجتماعي تحقيق در عمليات و برنامه نويسي در دانشگاه استنفورد گذاشته شد. پس از آن اين برنامه كامپيوتري كه با ايده تبديل داده هاي خام به اطالعات ضروري براي انجام تصميم گيري ها بنا شده بود در ساير دانشگاههاي امريكا نيز مورد استفاده قرار گرفت. در سال 975 دو نفر از سه نفر جوان فوق شركت SPSS را بنا نهادند و اين شركت به موفقيتهاي مالي زيادي از طريق فروش اين برنامه كامپيوتري دست يافت. از استفاده كنندگان اوليه SPSS كه وابسته به ارگانهاي دولتي بودند مي توان سازمان ناسا را نام برد. اولين نسخه هاي اين نرم افزار براي كامپيوترهاي بزرگ ( )Main frame كه اطالعات را از طريق كارت پانچ دريافت مي كردند طراحي شده بود. پس از SPSS DOS پيدايش كامپيوترهاي شخصي در سال 982 اولين نرم افزار آماري تحت سيستم عامل نرم افزار بود. با ظهور Windows به عنوان يك سيستم عامل نسخه تحت ويندوز اين نرم افزار نيز ارائه شد. طي اين سالها با توسعه امكانات سخت افزاري و نرم افزاري كامپيوترها اين نرم افزار نيز توسعه يافت. در سال 2009 شركت SPSS به كمپاني بزرگ IBM واگذار شد. نسخه هاي جديد اين نرم افزار ( از نسخه 8 به بعد( با نام PASW به بازار عرضه شده است و نام شركت SPSS از ژانويه 200 به شركت SPSS An IBM تغيير پيدا كرد. در ابتداي ورود به محيط SPSS دو پنجره با نام هاي Data View باز مي شود كه پنجره Data ماتريسي است و Variable View شامل تعداد زيادي سطر و ستون براي ورود داده ها و پنجره Variable براي معرفي متغيرها و ويرايش فايل داده است. نحوه ورود داده ها در پنجره Data طوري است كه اطالعات مربوط به هر فرد نمونه در يك رديف و اطالعات مربوط به هر متغير در يك ستون از اين جدول قرار مي گيرد. مثال اگر در تحقيقي بر روي 20 نفر دانشجو برخي ويژگي هاي آنان مانند جنسيت قد وزن و... اندازه گيري شده باشند و تعداد اين ويژگي ها 2 صفت باشد در اينصورت فايل داده ماتريسي است شامل 20 سطر و 2 ستون. 26
27 براي آشنايي با نحوه ورود داده ها در پنجره Data مثال زير را در نظر بگيريد: مثال: فرض كنيد در يك تحقيق بر روي گروهي از دانشجويان اين كالس برخي ويژگي هاي آنان توسط ابزار پرسشنامه اندازه گيري شده باشد در اينصورت پس از جمع آوري پرسشنامه ها ابتدا الزم است داده هاي اين پرسشنامه ها را استخراج كرده و در جدولي به شكل جدول زير تنظيم كنيم: در اين تحقيق فرض شده است كه تعداد دانشجويان يا همان نمونه 0 نفر بوده و بر روي هر فرد نمونه تعداد شش ويژگي اندازه گيري شده است. به عبارت ديگر پرسشنامه اي كه در اختيار هر فرد نمونه قرار گرفته است داراي شش سئوال جنسيت گروه خوني و است. بوده پس از جمع آوري پرسشنامه ها و قبل از اقدام به ورود داده ها به محيط SPSS توصيه مي شود ابتدا آنها را در... جدولي به شكل جدول فوق وارد كنيد. بدين منظور الزم است متغيرها را نامگذاري كرده و در مورد متغيرهاي كيفي مانند جنسيت گروه خوني پاسخهاي داده شده به سئواالت پرسشنامه و مانند اينها مقادير اين متغيرها را نيز كد گذاري كنيد. در مورد متغيرهاي كمي فقط كافي است متغيرها را نامگذاري كنيد چون مقادير اين متغيرها كميت بوده و نيازي به كد گذاري ندارند. در اين مثال براي نامگذاري متغيرها و نيز كد گذاري مقادير متغيرهاي كيفي به صورت زير عمل شده است. Lable: Jensiat X متغیر جنسیت: نام: 27
28 Lable: Goroh متغیر گروه خونی: X 2 نام: Lable: Ghad متغیر قد: X 3 نام: Lable: Moaddel متغیر معدل لیسانس: X 4 نام: Lable: Resht متغیرمیزان عالقه به رشته: X 5 نام: Lable: Amar متغیرمیزان عالقه به رشته آمار: نام: مقادير همان مقادير X 5 X 6 توجه : ويژگي هاي كمي را حتما به صورت كمي اندازه گيري كنيد. به عبارت ديگر در طراحي پرسشنامه براي اندازه گيري ويژگي هاي مختلف تا جائيكه بتوان آنها را به صورت كمي اندازه گيري كرد به هيچ عنوان آنها را به صورت كيفي و طبقه اي اندازه گيري نكنيد. چون در چنين صورتي قسمتي از اطالعات موجود در داده ها را دور ريخته ايد. مثال براي اندازه گيري وزن آن را به صورت 28
29 طبقه اي مانند " كمتر از 50" "50-60" "60-70" و... اندازه گيري نكنيد بلكه عدد وزن را ثبت كنيد. بعدا هرگونه طبقه بندي را به راحتي مي توان توسط SPSS انجام داد. پس از تنظيم داده ها در جدول فوق اطالعات اين جدول را به همين صورتي كه هست در پنجره Data وارد مي كنيم. يعني در اين پنجره داده هاي مربوط به جنسيت را در يك ستون داده هاي مربوط به گروه خوني در ستون ديگر و الي آخر. در چنين صورتي همانطوريكه مشاهده مي شود اگر مثال حجم نمونه 0 ستون خواهد بود. و تعداد متغيرها 20 باشد آنگاه فايل داده جدولي شامل 0 سطر و 20 پس از ورود داده ها در پنجره Data الزم است اين فايل را به نحو مناسبي ويرايش كنيم كه براي ويرايش فايل به پنجره Variable View مي رويم. در اين پنجره: پنجره Variable View در اين پنجره: ستون اول با عنوان مي شود. Name براي نامگذاري متغير ها است كه معموال در آمار از حرف و X X 2 و... براي نامگذاري متغير ها استفاده ستون دوم بعنوان Type براي تعيين نوع متغير است كه SPSS به صورت پيش فرض متغيرها را عددي 8 كاراكتري با دو نقطه اعشار در نظر مي گيرد اما با كليك كردن بر روي اين بخش مي توان نوع متغير را تغيير داد. با كليك كردن بر روي اين بخش پنجره اي باز مي شود كه در اين پنجره مي توان تعداد كاراكترهاي متغيرهاي عددي و نيز تعداد نقاط اعشار آنها را تغيير داد. مثال اگر داده ها بدون نقطه اعشار هستند مي توان Decimal places ان را صفر كرد تا داده ها در فايل داده بدون نقطه اعشار نشان داده شوند. همچنين براي داده هاي بزرگ مي توان از جدا كننده Dot يا Comma استفاده كرد. همچنين مي توان از نمادهاي علمي ( Scientific )notation استفاده كرد. از نمادهاي علمي نيز براي نشان دادن اعداد بزرگ يا اعداد كوچك بخصوص در علوم رياضي استفاده مي شود. مطابق با نمادهاي علمي مثال عدد 230 به صورت 3+.23E يعني نشان داده مي شود. همچنين عدد نشان داده مي شود به صورت E يعني 29
30 Decimals دو ستون بعدي با عناوين Width و تعداد كاركترهاي متغير عددي و نيز تعداد نقاط اعشاري آنها است. يعني همان ويژگي هايي كه در پنجره ستون بعدي با عنوان نيز ديده مي شود. نيز براي نامگذاري متغيرها است. Lable Type Lable در واقع نام ديگري براي متغير است منتها نامي كه در خروجي نشان داده مي شود و توصيه مي شود براي گذاري متغيرها از اسامي با مفهوم استفاده شود. Name نامي است كه در فايل Lable X داده نشان داده مي شود و Lable نامي است كه در خروجي نشان داده مي شود. مثال اگر متغير جنسيت را در فايل داده با نامگذاري كرديد براي Lable آن توصيه مي شود از " جنسيت" استفاده شود كه هم مي توان آن را به فارسي و يا انگليسي وارد كرد. استفاده از فونتهاي انگليسي داراي مشكالت كمتري است و توصيه مي شود از فونتهاي انگليسي استفاده شود. ستون بعدي با عنوان Lable براي گذاري مقادير متغير هاي كيفي است. متغيرهاي كيفي كه مقادير آن را كد گذاري كرده Values و كدها را در فايل داده وارد كرده ايد توصيه مي شود در اين بخش كدها را نشان دادن آن كدها ستون بعدي با عنوان به طور پيش فرض Lable Lable Missing ها را نشان خواهد داد. براي تعيين كد داده هاي گم شده است. در SPSS گذاري كنيد. چون در اينصورت در خروجي به جاي اگر خانه اي از جدول خالي گذاشته شود SPSS Missing آنرا فرض مي كند. اما در اين بخش مي توان براي داده هاي گم شده كد خاصي را در نظر گرفت. در حالت مبتدي توصيه مي شود اگر مقداري از يك متغير نامعلوم بود خانه مربوط به آن داده را خالي بگذاريد ستون بعدي با عنوان Columns تعداد ستون هاي در نظر گرفته شده براي هر متغير است كه به صورت پيش فرض متغير 8 ستون در نظر مي گيرد. اما مي توان آنرا تغيير داد. براي هر SPSS ستون بعدي با عنوان مكان قرار گرفتن داده ها در داخل متغيرها است كه به صورت پيش فرض داده ها در سمت راست Align هر متغير قرار مي گيرد. اما مي توان مكان آنرا تغيير داد. 3 Measure عنوان بعدي با ستون براي تعيين مقياس يا سطح اندازه گيري داده ها است. SPSS متغيرها را در سطح اسمي ترتيبي و كمي )فاصله اي و نسبتي( شناسايي مي كند. 30
31 تمرین : داده هاي مربوط به ويژگي هاي دانشجويان اين كالس را در پنجره Data نماييد. وارد كرده و اين فاصله را به نحو مناسبي ويرايش معرفي فایل Test 2 اين فايل محتوي داده هاي مربوط به تحقيقي بر روي يك نمونه تصادفي از دانش آموزان مقطع راهنمايي شهرستان مشهد در دو منطقه شمال و جنوب ( مرفه و محروم( اين شهرستان است. متغيرهاي اين فايل شامل: منطقه X جنسيت X 2 پايه تحصيلي و نمرات دروس رياضي علوم حرفه و فن زبان فارسي است به ترتيب X 8... X 4 X 3 توجه: بطور كلي در تهيه گزارش هاي آماري مثال فصل چهار پايان نامه الزم است ابتدا و قبل از انجام آزمون فرضيه ها توصيفي از نمونه بعمل آيد كه توصيف نمونه در مورد متغيرهاي كيفي در قالب تنظيم داده ها در جداول توزيع فراواني و رسم نمودارهاي ميله اي و دايره اي است و در مورد متغير هاي كمي در قالب محاسبه شاخص هاي آماري و رسم هيستوگرام فراواني است. براي تنظيم داد ه هاي متغيرهاي كيفي در جداول توزیع فراواني و رسم نمودار هاي ميله اي و دايره اي از مسير زير استفاده مي كنيم: مثال فرض كنيد بخواهيم جدول توزيع فراواني نمونه برحسب پايه تحصيلي را بدست آوريم در اينصورت پس از رفتن به مسير OK Variable فوق متغير مربوط به پايه تحصيلي ( X 3 ) را به قسمت مي بريم و بعد آن را مي كنيم. پس از اجراي اين فرمان نتيجه در قالب دو جدول و در خروجي خواهد آمد كه در اولين جدول گزارشي از داده هاي گم شده و داده هاي معتبر خواهد آمد و در دومين جدول توزيع فراواني نمونه بر حسب پايه تحصيلي خواهد آمد. اين جدول در زير آمده است. 3
32 GRADE Frequency Percent Valid Percent Cumulative Percent Valid FIRST SECOND THIRD Total در اين جدول ستون اول فراواني ستون هاي دوم و سوم به ترتيب درصد و درصد معتبر و آخرين ستون نيز درصد تجمعي شده است. تفاوت درصد و درصد معتبر در آن است كه در محاسبه درصد به حساب نمي آيند. Missing ها به حساب مي آيد اما در محاسبه درصد معتبر ها Missing براي رسم نمودارهاي ميله اي و دایره اي در پنجره Frequencies بر روي گزينه Charts كليك كرده و در پنجره باز شده نمودار مورد نظر را انتخاب مي كنيم. از نمودارهاي ميله اي Chart( )Bar و دايره اي Chart( )Pie براي متغيرهاي كيفي و از نمودار هيستوگرام براي متغيرهاي كمي استفاده مي شود. معموال از نمودار ميله اي براي نشان دادن فراواني ها و از نمودار دايره اي براي نشان دادن فراواني هاي نسبي يا درصدها استفاده مي شود. Chart Editor توجه: پس از رسم نمودار و در پنجره خروجي با دو بار كليك كردن بر روي هر نمودار به پنجره ديگري با نام مي رويم كه در اين پنجره مي توان نمودارمورد نظر را ويرايش نمود. تمرين: جدول توزيع فراواني متغيرهاي جنسيت منطقه و پايه تحصيلي را بدست آورده و در هر حالتي نمودارهاي ميله اي و دايره اي را نيز رسم كنيد. نمودار ميله اي را بر اساس فراواني ها و نمودار دايره اي را بر اساس درصدها رسم كنيد و اين نمودارها را كمي ويرايش كنيد. براي محاسبه شاخص هاي آماري متغيرهاي كمي از مسير زير استفاده مي كنيم. 32
33 مثال فرض كنيد بخواهيم شاخص هاي آماري نمرات درس رياضي دانش آموزان را بدست آوريم در اين صورت پس از رفتن به مسير فوق متغير مربوط به نمرات درس رياضي) X( 4 را به قسمت Variable مي بريم. با كليك كردن بر روي گزينه مي توان Option شاخصهاي آماري كه در خروجي نشان داه خواهد شد را تغيير داد. پس از اجراي اين فرمان نتيجه در قالب يك جدول و در خروجي خواهد آمدكه اين جدول و به صورت عمودي در زير آمده است. الزم به ذكر است كه در حالت معمولي اين جدول و نيز ساير جداول به صورت افقي در خروجي نشان داه خواهد شد كه در اينجا به جهت محدوديت مكاني آن را به صورت عمودي نشان داه ايم. Descriptive Statistics Valid N MATH. (listwise) N Statistic 3 3 Range Statistic 9.00 Minimum Statistic.00 Maximum Statistic Mean Statistic Std. Error.3454 Std. Deviation Statistic Variance Statistic Skewness Statistic -.82 Std. Error.068 Kurtosis Statistic Std. Error.35 در اين جدول سطر اول به عنوان N حجم نمونه است نمونه اي كه محاسبه بر روي آن انجام شده است يعني حجم نمونه بدون در نظر گرفتن داه هاي گمشده.. سطر دوم با عنوان Range دامنه تغييرات نمونه است كه دامنه تغييرات فاصله بين كمترين و بيشترين مقدار نمونه بوده و يكي از شاخصهاي پراكندگي است.. دو سطر بعدي جدول نيز مقادير كمينه و بيشينه نمونه است. دو سطر بعدي اين جدول با عنوان Mean به ترتيب ميانگين نمونه و خطاي استاندارد ميانگين نمونه است. خطای استاندارد يك آماره در واقع انحراف معيار آن آماره است. يعني شاخصي است كه مشخص مي كند مقدار يك آماره به طور 2/9605 و خطاي استاندارد آن حدود متوسط چقدر تا مقدار واقعي آن پارامتر فاصله دارد. مثال در اين مثال ميانگين نمونه 33
34 0/3454 مي باشد. اين بدان معنا است كه ميانگين واقعي جامعه كه يك پارامتر مجهول است برآورد مي شود كه حدود 2/96 0/34 كمتر يا بيشتر از 2/96 واريانس نمونه است. باشد و نيز برآورد مي شود كه اين ميانگين به طور متوسط حدود با عنوان باشد. ستون بعدي اين جدول Std.Deviation انحراف معيار نمونه) S ( و ستون بعدي نيز توجه: همانطوريكه مي دانيم واريانس شاخص پراكندگي است اما واحد اندازه گيري آن با واحد اندازه گيري داده ها يكسان نبوده بلكه مجذور يا مربع واحد اندازه گيري داده ها است. مثال اگر داده ها اندازه قد دانشجويان يك كالس بر حسب متر باشد آنگاه واحد اندازه گيري ميانگين داده ها نيز متر است حال آنكه واحد اندازه گيري واريانس آنها متر مربع خواهد بود. به همين منظور از واريانس جذر گرفته و جذر آن را انحراف معيار يا انحراف استاندارد ناميده اند كه واحد اندازه گيري انحراف معيار با واحد اندازه گيري داده ها يكسان و از انحراف معيار به عنوان شاخص پراكندگي استفاده شده است توجه: اگر ميانگين و انحراف معيار اندازه قد دانشجويان يك كالس بر حسب سانتي متر به ترتيب و باشد اين به آن معني است كه اندازه قد هر دانشجو در اين كالس به طور متوسط 70 سانتي متر است و نيز به طور متوسط قد هر دانشجو در اين كالس حدود 2 سانتي متر بيشتر يا كمتر از 70 است. دو سطر بعدي اين جدول با عنوان skewness به ترتيب چولگي و خطاي استاندارد آن است. چولگی شاخصي است براي اندازه گيري میزان تقارن يا عدم تقارن يك توزيع كه اگر توزيع متقارن باشد مانند توزيع نرمال چولگي آن صفر است. اما اگر توزيع نا متقارن بوده و دنباله آن به سمت راست كشيده شده باشد)چولگي به راست( ضريب چولگي آن عددي مثبت است و اگر توزيعي نامتقارن بوده و دنباله آن به سمت چپ كشيده شده باشد)چولگي به چپ( ضريب چولگي آن عدد منفي خواهد بود مانند اشكال زير. 34
35 توجه کنید كه در يك توزيع چوله به راست وزن يا فراواني داده هاي كوچك بيشتر از داده هاي بزرگ است و در توزيع چوله به چپ خالف آن است. مثال اگر چولگي نمرات درس آمار در يك كالس مثبت باشد ( چوله به راست( اين به آن معني است كه در اين كالس فراواني نمرات كوچك بيشتر از فراواني نمرات بزرگ است يا به عبارت ديگر در اين كالس اكثر دانشجويان نمراتي پايين تر از ميانگين گرفته اند. در مورد چولگي منفي خالف آن است. تقسیم بندی زیر در مورد ضريب چولگی برقرار است: در اين مثال همانطور يكه مشاهده مي شود ضريب چولگي 0/82 ت مي باشد. كه بيانگر كمي چوله به چپ بودن توزيع نمرات درس رياضي دانش آموزان است يعني در اين نمونه نمرات بزرگ كمي بيشتر از نمرات كوچك است. دو سطر آخر اين جدول با عنوان كشيدگي و خطاي استاندارد آن است. كشيدگي شاخصي است كه ميزان برجستگي يا Kurtosis ارتفاع يك توزيع نسبت به توزيع نرمال را نشان مي دهد كه در مورد توزيع نرمال كشيدگي صفر است و اگر كشيدگي يك توزيع بيشتر از نرمال باشد يعني پراكندگي آن كمتر از نرمال باشد ضريب كشيدگي عددي مثبت است و بالعكس اگر كشيدگي يك توزيع كمتر از نرمال باشد يا پراكندگي آن بيشتر از نرمال باشد ضريب كشيدگي عددي خواهد بود. منفی تقسیم بندی زیر در مورد ضريب كشيدگي برقرار است: 35
36 اگر توزيع تقريبا نرمال است. - اگر كشيدگي كمي بيشتر از نرمال يا پراكندگي كمي كمتر از نرمال است. -2 اگر كشيدگي بيشتر از نرمال و يا پراكندگي كمتر از نرمال است. -3 اگر كشيدگي كمي كمتر از نرمال و يا پراكندگي كمي بيشتر از نرمال است. -4 اگر كشيدگي كمتر از نرمال و يا پراكندگي بيشتر از نرمال است. -5 در اين مثال همانطوري كه مشاهده مي شود ضريب كشيدگي ت است كه اين بدان معنا است كه توزيع نمره رياضي دانش آموزان داراي كشيدگي خيلي كمتري نسبت به توزيع نرمال است يا به عبارت ديگر پراكندگي در توزيع نمره رياضي دانش آموزان نسبت به توزيع نرمال خيلي بيشتر است. تمرين: شاخص هاي آماري نمرات دروس مختلف را توسط فرمان Descriptive محاسبه كرده و نتايج حاصل را به نحو مناسبي تفسير كنيد. محاسبه شاخص های آماری يک متغیر کمی به تفکیک گروه های مختلف يک متغیر کیفی: براي محاسبه شاخص هاي آماري يك متغير كمي به تفكيك گروه هاي مختلف يك متغير كيفي از مسير زير استفاده مي كنيم. مثال فرض كنيد بخواهيم شاخص هاي آماري نمرات درس رياضي دانش آموزان را به تفكيك جنسيت محاسبه كنيم در اينصورت پس از رفتن به مسير فوق متغير مربوط به نمرات درس رياضي دانش آموزان را به قسمت X 4 Dependent List و متغير جنسيت را به قسمت مي بريم ( توجه داشته باشيد كه بطوركلي متغيرهاي كيفي كه افراد جامعه را به گروه هاي مجزا از هم Factor List تقسيم مي كند مانند جنسيت يا گروه خوني را فاكتور يا عامل نيز مي نامند(. 36
37 در قسمت پايين اين پنجره و در بخش Display مي توان مشخص كرد كه اين فرمان تنها شاخص هاي آماري را محاسبه كند يا نمودارهاي مربوطه را رسم كند و يا هر دو كار را انجام دهد. پيش فرض آن Both است. پس از اجراي اين فرمان نتيجه در قالب يك جدول و در خروجي خواهد آمد كه اين جدول در زير آمده است. Descriptives SEX Statistic Std. Error MATH. GIRL Mean % Confidence Interval for Mean Lower Bound 4.56 Upper Bound % Trimmed Mean Median Variance Std. Deviation Minimum 2.00 Maximum Range 8.00 Interquartile Range 8.50 Skewness Kurtosis BOY Mean % Confidence Interval for Mean Lower Bound Upper Bound.466 5% Trimmed Mean.86 Median.2500 Variance Std. Deviation Minimum.00 Maximum Range 9.00 Interquartile Range
38 Skewness Kurtosis اين جدول داراي 2 بخش اصلي است كه در هر بخشي شاخص هاي آماري نمرات درس رياضي به تفكيك براي دخترها و پسرها آمده است. در هر بخش از اين جدول اولين رديف ميانگين نمونه و خطاي استاندارد آن است. در اين مثال ميانگين نمونه و خطاي استاندارد آن براي نمرات درس رياضي دخترها به ترتيب 4/88 و 0/86 و در مورد پسرها به ترتيب /09 و 0/64 است. دو رديف بعدي اين جدول با عناوين Upper Bound و Lower Bound به ترتيب كرانهاي پايين و باالي يك فاصله اطمينان %95 براي ميانگين جامعه است كه مثال در مورد دخترها اين دو كران به ترتيب 4/56 و 5/2478 است. اين بدان معني است كه با %95 اطمينان ميانگين نمره رياضي دانش آموزان دختر )جامعه دانش آموزان دختر( حداقل 4/56 و حداكثر 5/2478 مي باشد. يعني در فاصله )5/2478 و ) 4/5478 قرار دارد. رديف بعدي اين جدول با عنوان %5 Trimmed mean ميانگين پيراسته 5 درصدي است. يعني %5 از داده هاي خيلي بزرگ و %5 از داده هاي خيلي كوچك كنار گذاشته شده و ميانگين داده هاي %90 وسط محاسبه شده است كه اين عمل به جهت حذف اثر داده هاي دور افتاده بر ميانگين انجام مي گيرد. رديف بعدي با عنوان Median ميانه نمونه است. ميانه نقطه وسط داه ها است يعني داده اي كه نيمي از داده ها كوچكتر يا مساوي آن است و يكي از شاخصهاي تمركز است. تفاوت ميانگين با ميانه در آن است كه ميانگين مركز ثقل داده ها است يعني ميانگين داده اي است كه وزن داده هاي سمت چپ و راست آن با يكديگر برابر است يا به عبارت ديگر ميانگين داده اي است كه مجموع انحرافات داده ها در سمت چپ و راست آن ( وزن داده ها در سمت چپ و راست آن( با يكديگر برابر است حال آنكه ميانه داده اي است كه تعداد داده هاي سمت چپ و راست آن با يكديگر برابر است. استفاده از ميانگين بسيار متداول تر از ميانه است چون از لحاظ تئوري ارزش ميانگين از ميانه بيشتر است اما با اين حال مواردي وجود دارد كه استفاده از ميانه به جاي ميانگين ترجيح داده مي شود. مثال هنگامي كه داده ها داراي داده هاي پرت يا دور افتاده ( داده هائي كه نسبت به ساير داده ها خيلي بزرگ يا خيلي كوچك است( است توصيه مي شود به جاي ميانگين از ميانه استفاده شود. همچنين هنگامي كه داده ها از يك متغير ترتيبي هستند بهتر است از ميانه استفاده شود. 38
39 رديف هاي بعدي به ترتيب واريانس انحراف معيار كمترين بيشترين و دامنه تغييرات) (Range نمونه است كه قبال راجع به آنها صحبت شد. رديف بعدي با عنوان Interquartile Range دامنه چارك ها است. يعني فاصله بين چارك اول تا چارك سوم كه يكي از شاخصهاي پراكندگي بوده و پراكندگي در نيمه مياني داده ها را اندازه گيري مي كند. دو رديف بعدي اين جدول نيز چولگي و كشيدگي و خطاي استاندارد آنها است كه راجع به آنها قبال صحبت شد. اين فرمان نمودارهاي جعبه اي Plot( )Box و نيز نمودار ساقه و برگ Plot( )Stem and Leaf را نيز رسم مي كند كه اين نمودارها جزو نمودارهاي اكتشافي است. نمودار ساقه و برگ در واقع شكل ديگري از هيستوگرام فراواني است كه فراواني ها نه به شكل ستونهاي پيوسته ( مانند آنچه كه در هيستوگرام رسم مي شود( بلكه توسط اعداد نشان داده خواهد شد. كاربرد نمودار جعبه اي بيشتر از نمودار ساقه و برگ است و به همين دليل راجع به آن كمي صحبت مي كنيم. نمودار جعبه ای Box Plot اين نمودار از روي مقادير كمترين بيشترين و چارك هاي اول دوم و سوم رسم مي شود و توسط اين نمودار عالوه بر اينكه توزيع يك متغير دريك گروه مورد بررسي قرار مي گيرد گروه هاي مختلف را نيز مي توان توسط آن با يكديگر مقايسه كرد. نمونه اي از يك نمودار جعبه اي در زير رسم شده است. در اين نمودار خط پايين نمودار بيانگر كمترين مقدار نمونه قاعده پائين نمودار بيانگر چارك اول خط مياني بيانگر چارك دوم يا همان ميانه قاعده باال بيانگر چارك سوم و خط باالي نمودار نيز بيانگر بيشترين مقدار نمونه است. توجه كنيد كه چارك اول داده اي است كه يك چهارم يا 25 درصد از داده ها كوچكتر يا مساوي آن است چارك دوم يا همان ميانه داده اي است كه دو چهارم يا پنجاه درصد از داده ها حداكثر مساوي آن است و چارك سوم داده اي است كه سه چهارم يا 75 درصد از داده ها حداكثر مساوي آن است. 39

40 نمودار جعبه اي نمرات درس رياضي دخترها و پسرها در زير آمده است. توجه كنيد كه مطابق اين نمودار نيز مي توان چوله به چپ بودن توزيع نمره رياضي دخترها و تقريبا متقارن بودن توزيع نمره رياضي پسرها ( چيزي كه از مقدار شاخص چولگي آنها نيز مشخص بود( را مشاهده كرد. همچنين مطابق آنچه كه از اين نمودار پيداست توزيع نمره رياضي دخترها از وضعيت خيلي بهتري نسبت به پسرها برخوردار است. Explore تمرين: توسط فرمان شاخص هاي آماري نمرات دروس مختلف را به تفكيك جنسيت منطقه پايه تحصيلي محاسبه كرده و آنها را تفسير كنيد. همچنين نمودار جعبه اي مربوط را رسم كرده و آنرا كمي ويرايش كنيد. 40
41 تشکیل جدول توزيع فراوانی بر حسب دو متغیر کیفی ( جدول متقاطع(: در مواردي ممكن است بخواهيم توزيع فراواني نمونه بر حسب دو متغير كيفي را به صورت يك جدول متقاطع ( توافقي( بدست آوريم بدين منظور از مسير زير استفاده مي كنيم: مثال فرض كنيد بخواهيم توزيع فراواني نمونه بر حسب جنسيت و پايه تحصيلي را به شكل جدولي مانند جدول زير بدست آوريم: بدين منظور پس از رفتن به مسير فوق يكي از اين دو متغير را به قسمت Row )سطر( و ديگري را به قسمت Column )ستون( مي بريم و پس از اجراي اين فرمان نتيجه در قالب يك جدول متقاطع و در خروجي خواهد آمد كه اين جدول به شكل انگليسي آن در زير نيز آمده است. SEX * GRADE Crosstabulation Count GRADE FIRST SECOND THIRD Total SEX GIRL BOY Total توجه کنید كه در يك جدول متقاطع دو بعدي سه نوع درصد مي توان محاسبه كرد: 4
42 درصدي كه بر پايه جمع هاي سطري محاسبه مي شود بنام درصد سطري. درصدي كه بر پايه جمع هاي ستوني محاسبه مي شود بنام درصد ستوني. درصدي كه بر پايه جمع كل نمونه محاسبه مي شود بنام درصد كل. ) )2 )3 براي محاسبه چنين درصدهايي در پنجره بر روي گزينه Cell كليك كرده و در قسمت Percentages نوع درصد Cross Tabs مورد نظر را انتخاب مي كنيم. تمرين: جدول توزيع فراواني نمونه بر حسب متغير هاي )جنسيت/منطقه( )جنسيت/پايه تحصيلي( و ( پايه تحصيلي و منطقه( را به صورت يك جدول متقاطع بدست آورده و در هر حالتي درصدهاي سطري ستوني و كل را نيز محاسبه كنيد.»آمار استنباطی«همانطور كه در مقدمه نيز بيان شد موضوع آمار استنباطي مطالعه یک جامعه از روی داده های یک نمونه از آن جامعه است. به عبارت ديگر در آمار استنباطي فرض بر اين است كه به داليل مختلف امكان مشاهده جامعه آماري نبوده بلكه تنها مي توان به يك نمونه از آن جامعه دسترسي داشت. لذا هر گونه استنباط و استنتاج درباره جامعه بايد از طريق داده هاي يك نمونه از آن جامعه بنابر اين انجام گيرد. اولین گام در موضوع آمار استنباطي چگونگي و روش نمونه گيري از يك جامعه است. واضح است كه به روش هاي مختلف مي توان از يك جامعه آماري نمونه گرفت اما در آمار نمونه بايد تصادفی باشد و منظور از يك نمونه تصادفي نمونه اي است كه در آن همه افراد جامعه شانسي براي انتخاب در نمونه را داشته باشند و اين شانس براي همه افراد جامعه يكسان باشد كه چنين نمونه اي را نمونه نا ا ريب نيز مي نامند. يعني نمونه اي كه مي تواند به خوبي معرف جامعه اش باشد و همه خواص جامعه را شامل است. براي اخذ يك نمونه تصادفي از يك جامعه روش هاي مختلفي وجود دارد كه اين روش ها 42
43 بنابر نوع موضوع تحت مطالعه و چگونگي توزيع جامعه متفاوت از يكديگرند. اما عمده ترين روش هاي كالسيك نمونه گيري كه اكثرا از اين روش ها و يا تركيبي از آنها استفاده مي شود به شرح زير است: نمونه گیری تصادفی ساده نمونه گیری تصادفی منظم )سیستماتیک( نمونه گیری طبقه ای نمونه گیری خوشه ای)شکل کوچک شده از جامعه( ) )2 )3 )4 نمونه گيري تصادفي ساده نمونه گيري تصادفي ساده پايه و اساس همه روشهاي نمونه گيري آماري است. در اين روش نمونه به نحوي انتخاب مي شود كه همه افراد جامعه شانسي براي انتخاب در نمونه را داشته و اين شانس براي همه افراد يكسان باشد. نمونه گيري تصادفي ساده را مي توان به دو روش با جايگذاري و بدون جايگذاري انجام داد. در روش با جايگذاري هر فرد جامعه مي تواند بيش از يكبار در نمونه انتخاب شود حال آنكه در روش بدون جايگذاري هر فرد جامعه فقط يكبار شانسي براي انتخاب در نمونه را دارد. براي انتخاب يك نمونه تصادفي ساده از يك جامعه مي توان از روشهاي مختلفي استفاده كرد. مثال مي توان به هر فرد جامعه يك شماره نسبت داده و سپس با استفاده از جدول اعداد تصادفي و به تعداد نمونه مورد نظر افرادي از آن جامعه را انتخاب كرد. البته امروزه با وجود برنامه هاي كامپيوتري مي توان به جاي استفاده از جدول اعداد تصادفي از اين برنامه ها در توليد اعداد تصادفي كمك گرفت. نمونه گيري تصادفي منظم )سيستماتيک( از اين روش هنگامي استفاده مي شود كه ليستي از افراد جامعه در دسترس باشد. در اين روش ابتدا گامي از قبل تعيين مي شود و گام يك عدد صحيح مثبت مانند است كه معموال آن را از رابطه به دست مي آورند كه در آن N حجم جامعه k=n/n k 43
44 حجم نمونه است. سپس از بين اعداد صحيح تا k يك عدد به تصادف انتخاب مي شود. فرد متناظر با عدد انتخاب شده و n اولين عضو نمونه است و ساير اعضاي نمونه به تعداد گام مورد نظر به نمونه اضافه مي شوند. بنابر اين در اين روش اولين عضو نمونه بصورت تصادفي انتخاب شده و ساير اعضاي نمونه وابسته به نفر اول به نمونه وارد مي شوند. مثال فرض كنيد بخواهيم از يك جامعه = 000 N نفره يك نمونه = 00 n تائي به روش سيستماتيك انتخاب كنيم و نيز فرض كنيد ليستي از افراد جامعه در دسترس باشد. در اين صورت ابتدا گام حركت را به صورت K=N/n=000/00=0 تعيين مي كنيم. سپس از 4 0 بين اعداد صحيح تا يك عدد به تصادف انتخاب مي كنيم. فرض كنيد عدد انتخاب شده باشد. در اين صورت فرد 4 +0= 24 رديف چهارم در ليست افراد جامعه اولين عضو نمونه است. ساير اعضاي نمونه افراد رديفهاي 4= =984+0 هستند =34 نمونه گيري طبقه اي از اين روش هنگامي استفاده مي شود كه افراد جامعه به گروههاي مجزا از يكديگر افراز شده باشند و اين گروه بندي به نحوي باشد كه افرادي كه داخل هر گروه قرار مي گيرند متجانس اما گروههاي مختلف نا متجانس باشند. به عبارت ديگر واريانس يا پراكندگي در داخل هر گروه كم اما بين گروهها زياد باشد. چنين گروههائي را طبقه گويند. در روش طبقه اي نمونه به نحوي انتخاب مي شود كه از هر طبقه اي به نسبت حجم آن طبقه تعدادي در نمونه داشته باشيم. مثال فرض كنيد بخواهيم توسط نمونه گيري از يك شهر بزرگ درآمد ماهانه خانوارهاي آن شهر را برآورد كنيم و نيز فرض كنيد خانوارهاي اين شهر را بتوان از لحاظ درآمد به گروههاي كم درآمد درآمد متوسط درآمد باال و درآمد خيلي باال تقسيم كرد. در اين صورت هر كدام از اين گروههاي درآمدي يك طبقه را تشكيل مي دهند چون خانوارهائي كه در اين گروهها قرار ميگيرند از لحاظ درآمدي شبيه به يكديگر بوده اما خانوارهاي گروههاي مختلف از لحاظ درآمدي متفاوت از يكديگر هستند. به عبارت ديگر واريانس يا پراكندگي درآمد در بين خانوارهاي هر كدام از اين گروهها كم اما بين گروهها زياد است. بنابر اين اين گروهها را طبقه گفته و براي نمونه گيري از روش نمونه گيري طبقه اي استفاده مي كنيم. به اين ترتيب كه از همه اين گروههاي درآمدي يا همان طبقات نمونه مي گيريم اما از هر طبقه اي به نسبت حجم آن طبقه نمونه مي گيريم. مثال اگر طبقه افراد با درآمد پايين 20 درصد از افراد جامعه را تشكيل دهند در اين صورت 20 درصد از حجم نمونه را به اين طبقه اختصاص مي دهيم و به همين ترتيب الي آخر. 44
45 نمونه گيري خوشه اي از اين روش نيز هنگامي استفاده مي كنيم كه افراد جامعه به گروه هاي مجزا از يكديگر افراز شده باشند با اين تفاوت كه در اين حالت گروه بندي به نحوي است كه افرادي كه داخل هر گروه قرار مي گيرند نامتجانس اما گروه هاي مختلف متجانس هستند. به عبارت ديگر واريانس يا پراكندگي در داخل هر گروه زياد اما بين گروهها كم است. يعني در واقع هر كدام از اين گروه ها را مي توان نمونه كوچك شده اي از كل جامعه در نظر گرفت كه همه خواص جامعه را شامل است. چنين گروه هايي را خوشه مي ناميم. در نمونه گيري خوشه اي تعدادي از خوشه ها به تصادف انتخاب شده و آنها را سرشماري مي كنند. و يا در صورت بزرگ بودن خوشه ها پس از انتخاب خوشه هاي نمونه از آنها يك نمونه تصادفي انتخاب مي شود ( خوشه اي دو مرحله اي ) و يا ممكن است پس از انتخاب خوشه هاي نمونه از هر كدام از اين خوشه ها نمونه به روش طبقه اي انتخاب كرد و يا حتي مجددا خوشه هاي نمونه را خوشه بندي كرده و از آنها به روش خوشه اي نمونه گرفت ( خوشه اي چند مرحله اي ). در هر صورت در روش خوشه اي از همه خوشه هاي جامعه نمونه گرفته نمي شود بلكه تنها از تعدادي از آنها نمونه گرفته مي شود. در مسائل عملي و كاربردي ممکن است از یکي از این روشها و یا از تركيبي از آنها استفاده شود. مثال فرض كنيد در يك تحقيق هدف تعيين ميزان تاثير برگزاري دوره هاي آموزشي براي كارشناسان كنترل كيفيت صنايع مختلف باشد. به عبارت ديگر مي خواهيم مشخص كنيم كه آيا دوره هاي آموزشي برگزار شده توسط سازمان صنايع براي كارشناسان كنترل كيفيت كارخانجات توليدي در افزايش معلومات و بهبود كاركرد آنها موثر بوده است يا خير فرض كنيد واحدهاي توليدي در پنج صنعت مختلف صنايع غذائي صنايع نساجي قطعات خودرو سيمان و صنايع مبلمان مشغول فعاليت باشند. در اين تحقيق جامعه آماري مجموعه كليه كارشناسان كنترل كيفيت واحدهاي توليدي اين پنج صنعت است. اگر بپذيريم كه چگونگي كنترل كيفيت ( توزيع متغير تحت مطالعه( در صنايع مختلف متفاوت از يكديگر است آنگاه هر كدام از اين صنايع تشكيل يك طبقه مي دهند و در اولين گام براي نمونه گيري بايد از روش طبقه اي استفاده كرد. بدين ترتيب كه از واحدهاي توليدي هر كدام از اين صنايع بايد نمونه گرفت و حجم نمونه اختصاص داده شده به هر صنعت بايد متناسب با حجم واحدهاي توليدي آن صنعت باشد. در هر كدام از اين صنايع تعدادي واحد توليدي مشغول به فعاليت هستند. اگر بپذيريم كه در هر صنعتي واحدهاي توليدي مختلف از لحاظ وضعيت كنترل كيفيت شبيه به هم هستند ( توزيع متغير تحت مطالعه در اين واحدها يكسان است( در اينصورت هر كدام از واحدهاي توليدي در هر صنعتي تشكيل يك خوشه مي دهد و بنابراين براي نمونه گيري از اين 45
46 واحدها نيازي به اخذ نمونه از همه آنها نيست بلكه كافي است تعدادي از اين واحدها را به عنوان خوشه هاي نمونه انتخاب كرده و آن خوشه ها را سرشماري كرد. يعني كارشناسان كنترل كيفيت آن واحدها را مورد بررسي و مطالعه قرار داد. در برخي موارد حجم خوشه هاي انتخابي در نمونه زياد است كه در چنين صورتي پس از انتخاب خوشه هاي نمونه از هر خوشه اي يك نمونه تصادفي گرفته مي شود. بر اين اساس در اين تحقيق با توجه به توزيع متغير تحت مطالعه براي نمونه گيري از اين جامعه آماري در ابتدا جامعه طبقه بندي شده و نمونه به روش طبقه اي انتخاب شده است. سپس در هر طبقه اي واحدها تشكيل خوشه داده اند و بنابر اين در هر طبقه اي براي نمونه گيري از روش خوشه اي استفاده شده است. اگر تعداد افراد در هر خوشه ( كارشناسان كنترل كيفيت در هر واحد انتخابي در نمونه( كم باشد خوشه ها سرشماري مي شوند) همه كارشناسان كنترل كيفيت در واحدهاي توليدي انتخاب شده در نمونه مورد بررسي و مطالعه قرار مي گيرند( اما اگر حجم خوشه ها زياد باشد پس از انتخاب خوشه هاي نمونه از هر كدام از آنها يك نمونه تصادفي گرفته مي شود. پارامتر )Parameter( هر ویژگی عددی يک جامعه را يك «پارامتر» گوييم. پارامترها مقادير ثابتي هستند كه در عمل هميشه مجهولند. مثال ميانگين و واريانس يك جامعه )µ و ) پارامترند )براي جامعه ثابت مي باشند(. آماره )Statistic( هر ویژگی عددی يک نمونه از يك جامعه را «آماره» مي گويند. مثال ميانگين و واريانس نمونه برخالف پارامترها ثابت نبوده بلكه متغير تصادفي هستند. آماره هستند. آماره ها روش های برآورد پارامترها بطوركلي پارامترها را به دو روش نقطه اي و فاصله اي برآورد مي كنند. در روش نقطه اي پارامتر جامعه توسط آماره اي در نمونه برآورد ميشود. مثال ميانگين جامعه توسط میانگین نمونه برآورد مي شود. اما در روش فاصله اي كه آنرا فاصله اطمینان نيز مي نامند پارامتر جامعه توسط يك فاصله برآورد مي شود. فاصله اي كه با ضريب اطمينان خوبي پارامتر جامعه را در بر مي گيرد. 46
47 آزمون فرض يكي ديگر از روشهاي برآورد و تعيين پارامترها استفاده از آزمون فرض است. در آزمون فرض از قبل يك ادعا يا حدس يا گماني بر روي پارامتر يا پارامترهاي جامعه وجود دارد كه مي خواهيم توسط داده هاي يك نمونه تصادفي از آن جامعه آن ادعا را مورد بررسي قرار دهيم. فرض صفر يا H 0 و فرض خالف ( جانشین :) H A يا H فرضيه اي كه قرار است مورد آزمون قرار گيرد و معموال بيانگر عدم وجود اختالف يا ارتباط بين پارامترها است را فرض صفر گفته و آن را با H 0 نشان مي دهند. نقيض فرض صفر را فرض خالف يا فرض جانشین گفته و آن را با H يا H A نشان مي دهيم. خطا ها: در هر آزمون فرضيه همواره فرض صفر آزمون مي شود و اين فرضيه گزاره اي است كه ارزش آن درست يا نادرست است. از طرفي مطابق با داده هاي نمونه و روشي كه در آزمون فرضيه به كار ميبريم ما فرضيه را رد كرده يا آن را رد نمي كنيم. لذا چهار حالت ممكن است بوجود آيد به شرح زير. فرض صفر ( 0 H( درست است و آن را مي پذيريم. فرض صفر ( 0 H( درست است و آن را رد مي كنيم. فرض صفر ( 0 H( نادرست است و آن را مي پذيريم. فرض صفر ( 0 H( نادرست است و آن را رد مي كنيم. ) )2 )3 )4 واضح است كه از اين چهار حالت ممكن فوق در حاالت 2 و 3 دچار خطا شده ايم. حالت 2 نوع دوم گويند. به عبارت ديگر: را خطای نوع اول و حالت 3 را خطای خطای نوع اول : خطاي ناشي از رد كردن فرض صفر وقتي كه اين فرض درست است. 47
48 خطای نوع دوم: خطاي ناشي از پذيرفتن فرض صفر وقتي اين فرض غلط است. سطح خطای آزمون ( سطح معنی داری آزمون (: α: احتمال رخ دادن خطاي نوع اول را سطح خطا يا سطح معني داري آزمون گفته و آن را با α نمايش مي دهيم. : ß احتمال رخ دادن خطاي نوع دوم را با ß نشان مي دهند. لزوما ß α رابطه و بين توجه : معكوس برقرار بوده اما حاصل جمع آن ها لزوما مساوي يك نيست. يعني اين دو پيش آمد پيشامدهاي مكمل يكديگر نيستند. در آمار α را از قبل ثابت در نظر گرفته و براي آن معموال مقادير 0/0 يا 0/05 را در نظر مي گيرند كه با ثابت بودن α رابطه اي معكوس بين حجم نمونه و ß برقرار است و لذا يكي از راه هاي كاهش ß افزايش حجم نمونه است. توان آزمون: احتمال رد كردن فرض صفر وقتي اين فرض غلط است را «توان آزمون» گفته و معموال آن را با π )عدد پي( نشان مي دهند. توجه: بين توان آزمون و ß رابطه اي معكوس برقرار بوده و حاصل جمع آنها مساوي يك است. از آنجايي كه بين حجم نمونه و ß رابطه اي معكوس برقرار است لذا بين حجم نمونه و توان آزمون رابطه اي مستقيم برقرار است. يعني با افزايش حجم نمونه ß كاهش يافته و توان آزمون افزايش مي يابد. آماره آزمون: مالك يا معيار ي است كه از روي داده هاي نمونه محاسبه شده است و توسط آن در مورد رد كردن يا رد نكردن فرض صفر تصميم گيري مي شود. 48
49 ناحیه رد ( ناحیه بحرانی(: ناحيه اي است در دامنه توزيع آماره آزمون بطوريكه هرگاه مقدار آماره در آن ناحيه قرار گيرد فرض صفر رد مي شود. توجه: روش سنتي در انجام آزمون فرضيه ها استفاده از آماره آزمون و تعيين ناحيه بحراني است. بدين ترتيب كه ابتدا آماره آزمون توسط فرمول مربوطه محاسبه شده و سپس مقدار آن با مقدار بحراني جدول توزيع احتمال مربوط به آن مقايسه شده و بنابراينكه مقدار آماره در ناحيه بحراني قرار گيرد يا خير در مورد آن فرضيه تصميم گيري مي شود. اما در استفاده از نرم افزار ها در انجام آزمون هاي آماري اگرچه اين نرم افزار ها آماره آزمون را محاسبه كرده و در خروجي ارائه ميدهند اما نيازي به اين آماره و تعيين ناحيه بحراني نيست. چون اين نرم افزارها شاخصي با نام P.Value را در خروجي ارايه مي دهند كه تصميم گيري در مورد فرضيه توسط اين شاخص انجام مي گيرد. :P-Value كه آن را P -مقدار يا مقدار احتمال نيز مي نامند عددي است بين صفر و يك كه هر چقدر اين عدد بزرگتر باشد به P-Value معناي آن است كه فرض صفر درست بوده و نبايد آن را رد كرد و هر چقدر اين عدد كوچك باشد به معناي نادرست بودن فرض صفر بوده و لذا بايد آن فرضيه را رد كرد. در عمل P.Value را با سطح خطاي آزمون )α( مقايسه مي كنند. اگر شد α كمتر از ) فرض صفر را رد كرده و در غير اين صورت آن را رد نمي كنيم. P.Value<α ( P.Value توجه: اگر فرضيه اي در سطح خطاي %5 پذيرفته شود )P.Value>0/05( آنگاه P-value ي آن از 0/05 بزرگتر بوده و لذا از نيز بزرگتر خواهد بود و در نتيجه اين فرضيه در سطح خطاي 0/0 نيز پذيرفته خواهد شد. اگر فرضيه اي در سطح 0/0 خطاي % رد شود) P.Value<0/0 ( آنگاه P-value ي آن از 0/0 كوچكتر است و لذا از 0/05 نيز كوچكتر خواهد بود و در نتيجه اين فرضيه در سطح خطاي 0/05 نيز رد خواهد شد. اما اگر فرضيه اي در سطح خطاي %5 رد شود در سطح خطاي % نتيجه اي از آن بدست نمي آيد و به طور مشابه اگر فرضيه اي در سطح خطاي % پذيرفته شود آنگاه در سطح خطاي %5 نتيجه اي از آن بدست نمي آيد. 49
50 آزمون تساوی میانگین با يک عدد ثابت: H 0 :µ= µ 0 µ 0 فرض كنيد µ ميانگين يك جامعه نرمال و يك مقدار ثابت باشد مي خواهيم فرضيه را آزمون كنيم. بدين منظور از مسير زير استفاده مي كنيم: 2 مثال فرض كنيد بخواهيم ميانگين نمرات درس رياضي دانش آموزان را با عدد مقايسه كنيم يعني در واقع مي خواهيم فرضيه µ= 2 H 0 : كه در آن µ بيانگر ميانگين نمرات درس رياضي دانش آموزان است را آزمون كنيم. بدين منظور پس از رفتن به مسير فوق متغير مربوط به نمرات درس رياضي دانش آموزان ( 4 X( را به قسمت Test Variable برده و عدد ثابت و يا همان 2 را در قسمت Test Value نتيجه در قالب دو جدول و در خروجي خواهد آمد كه اين جداول در زير آمده است. وارد مي كنيم و فرمان را اجرا مي كنيم. پس از اجراي اين فرمان One-Sample Statistics N Mean Std. Deviation Std. Error Mean MATH One-Sample Test Test Value = 2 95% Confidence Interval of the Difference t df Sig. (2-tailed) Mean Difference Lower Upper MATH در اولين جدول گزارشي از برخي شاخص هاي آماري اين متغير يعني نمرات درس رياضي دانش آموزان آمده است. سپس در دومين جدول نتيجه انجام اين آزمون آمده است. در اين جدول ستونهاي اول و دوم با عناوين t و df به ترتيب مقدار آماره آزمون همان P.Value ي اين آزمون است كه در ( آماره t( و درجه آزادي آن است. سومين ستون اين جدول با نام (2-Tailed) Sig 50
51 اين مثال همانطور كه مشاهده مي شود P.Value خيلي كوچك بوده و دست كم تا سه رقم اعشار صفر است. بنابراين فرض صفر مبني بر يكسان بودن اين ميانگين با عدد 2 در سطح خطاي 0/0 )و در نتيجه در سطح خطاي 0/05( رد مي شود. دو ستون آخر اين جدول با عناوين Lower و به ترتيب كران هاي پايين و باالي يك فاصله اطمينان %95 براي Upper اختالف ميانگين با عدد µ 0 يعني -µ µ 0 است. در اين فاصله: µ - µ 0 < 0 %95 اگر هر دو كران فاصله مثبت باشد اين به آن معني است كه با اطمينان )مثبت( است. يعني ) H : µ > µ 0 پذيرفته مي شود. مي باشد. بنابر اين فرضيه H 0 : µ = µ 0 رد شده و به جاي آن فرضيه µ > µ 0 µ- µ 0 < 0 اگر هر دو كران فاصله منفي باشد اين به آن معني %95 است كه با اطمينان )منفي( است يعني )2 رد شده و به جاي آن فرضيه H : µ < µ 0 پذيرفته مي شود. H 0 : µ = است. بنابر اين فرضيه µ 0 µ < µ 0 3( اگر كران پايين فاصله منفي و كران باالي آن مثبت باشد يعني صفر در اين فاصله قرار گيرد اين به آن معني است كه با %95 اطمينان 0= 0 µ- µ است. يعني µ = µ 0 است. بنابر اين فرضيه H 0 : µ = µ 0 پذيرفته مي شود. در اين مثال همانطور كه مشاهده مي شود هر دو كران اين فاصله مثبت است و بنابر اين با %95 اطمينان فرضيه 2= µ H 0 : رد شده و به جاي آن فرضيه <µ 2 H : پذيرفته مي شود. يعني ميانگين نمره رياضي دانش آموزان بطور معني داري از 2 بيشتر است. از طرفي چون كران پايين اين فاصله حدود ~ 0/7 0/69 و كران باالي آن حدود 0/7 2 است. لذا مي توان نتيجه گرفت كه با %95 اطمينان اختالف اين ميانگين با عدد و حداقل /22 ~ /2 حداكثر /2 است. يا به عبارت ديگر با %95 اطمينان ميانگين نمره رياضي دانش آموزان حداقل 0/7 و حداكثر /2 از 2 بيشتر است يعني اين ميانگين با 95 درصد اطمينان بين دو عدد 2/7 تا 3/2 قرار دارد. 5
52 انتخاب گروهی خاص در نمونه : تمرين ميانگين نمرات دروس مختلف را با عدد µ 0 مقايسه كنيد. را به نحوي انتخاب كنيد كه يكبار فرضيه رد شده و به جاي آن µ 0 H : µ<µ 0 فرضيه H : µ > µ 0 پذيرفته شود. يكبار فرضيه رد شده و به جاي آن فرضيه پذيرفته شود و بار ديگر نيز فرضيه H 0 : µ = µ 0 پذيرفته شود. اين تمرين را يكبار بر روي كل نمونه انجام دهيد. يكبار به تفكيك جنسيت بار ديگر به تفكيك پايه تحصيلي. يكبار به تفكيك جنسيت و منطقه و يكبار نيز به تفكيك جنسيت و منطقه و پايه تحصيلي انجام دهيد. در انجام اين تمرين يكبار از فرمان Select Case استفاده كرده و يكبار از Split كردن فايل استفاده كنيد. آزمون تساوی دو میانگین در نمونه های مستقل: و µ فرض كنيد ميانگين و واريانس يك جامعه نرمال و و µ 2 ميانگين و واريانس يك جامعه نرمال ديگر باشند. مي خواهيم فرضيه يكسان بودن ميانگين هاي اين دو جمعيت يعني H 0 : µ = µ 2 را آزمون كنيم. قبل از آزمون اين فرضيه الزم است فرض يكسان بودن واريانس هاي اين دو جمعيت يعني فرضيه = : 0 H آزمون شود. چون بنابر اين كه واريانس هاي اين دو جمعيت يكسان بوده يا يكسان نباشد روش انجام آزمون تساوي دو ميانگين كمي متفاوت است كه البته SPSS بطور خودكار قبل از آزمون تساوي دو ميانگين فرضيه يكسان بودن واريانس ها را آزمون مي كند. براي انجام آزمون تساوي دو ميانگين در نمونه هاي مستقل از مسير زير استفاده مي كنيم. مثال فرض كنيد بخواهيد نمره رياضي دانش آموزان دختر و پسر را با يكديگر مقايسه كنيم يعني در واقع مي خواهيم فرضيه µ 2 و به ترتيب بيانگر ميانگين نمره رياضي دانش آموزان دختر و پسر است را آزمون كنيم. به كه در آن µ H 0 : µ = µ 2 52
53 Test Variable اين منظور پس از رفتن به مسير فوق متغير مربوط به نمره رياضي دانش آموزان ( 4 X( را به قسمت برده و متغير جنسيت را به قسمت Grouping Variable برده و كد مربوط به جنسيت دختر و پسر را براي آن تعريف مي كنيم. پس از اجراي اين فرمان نتيجه در قالب دو جدول و در خروجي خواهد آمد كه اين جداول در زير آمده است. متذكر مي شويم كه در حالت معمولي جدول دوم در خروجي به صورت سطري )افقي( نشان داده خواهد شد كه به جهت كمبود جا در اينجا جاي سطرها و ستونهاي آن عوض شده و به صورت ستوني )عمودي( نشان داده شده است. Group Statistics SEX N Mean Std. Deviation Std. Error Mean MATH. GIRL BOY Independent Samples Test MATH. Levene's Test for Equality of Variances Equal variances assumed F Sig..000 Equal variances not assumed t-test for Equality of Means T Df Sig. (2-tailed) Mean Difference Std. Error Difference % Confidence Interval of the Difference Lower Upper در اولين جدول گزارش از برخي از شاخص هاي آماري نمرات درس رياضي به تفكيك جنسيت آمده است. در دومين جدول نتيجه آزمون تساوي دو واريانس و دو ميانگين آمده است. دو سطر اول اين جدول با عنوان Levene's Test for Equality of H 0 : : = variances نتيجه آزمون تساوي دو واريانس يا همان آزمون فرضيه است كه دومين سطر آن با عنوان همان Sig. P-value ي اين آزمون است و در اين مثال طوري كه مشاهده مي شود P.value ي اين آزمون خيلي كوچك بوده و دسته كم 53
54 تا سه رقم اعشاري است. بنابر اين اين فرض يكسان بودن واريانس هاي دو جمعيت در سطح خطاي )%( 0/0 و در نتيجه سطح خطاي %5 رد مي شود. بر اين اساس واريانس يا پراكندگي در توزيع نرمال نمرات درس رياضي دانش آموزان دختر و پسر يكسان نبوده و بطور معني داري متفاوت از يكديگر است. فرضيه H 0 : µ = µ 2 است كه در دو ستون آمده است. ادامه اين جدول نتيجه آزمون تساوي دو ميانگين يا همان آزمون ستون اول با فرض يكسان بودن واريانس ها و ستون دوم با فرض عدم تساوي واريانس ها است. به عبارت ديگر اگر فرض يكسان بودن واريانس ها پذيرفته شود در ادامه اين جدول از اطالعات ستون اول آن استفاده مي كنيم و در غير اين صورت از اطالعات رديف دوم آن استفاده مي كنيم. در اين مثال با توجه به اينكه فرض يكسان بودن واريانس ها رد شد لذا در ادامه اين جدول از اطالعات ستون دوم بايد استفاده كنيم. در ادامه اين جدول رديفهاي اول و دوم با عناوين t و df به ترتيب آماره آزمون ( آماره t( و درجه آزادي آن است كه اولين آن با فرض يكسان بودن واريانسها و دومي با فرض عدم تساوي واريانسها است. Sig.(2-Taied) سومين رديف در اين قسمت از جدول با عنوان همان P-valueي آزمون تساوي دو ميانگين است كه در اين مثال همانطور كه مشاهده مي شود مقدار آن در هر دو حالت يكسان بودن يا يكسان نبودن واريانسها خيلي كوچك بوده و تا سه رقم اعشار صفر است. بنابر اين فرض يكسان بودن ميانگين هاي اين دو جمعيت در سطح خطاي % )0/0( و در نتيجه در سطح خطاي 5 درصد رد مي شود. به عبارت ديگر ميانگين نمره رياضي دخترها و پسرها يكسان نبوده بلكه به طور كامال معني داري متفاوت از يكديگر است. در انتهاي اين جدول و آخرين دو سطر آن با عناوين Lower Upper و به ترتيب كران هاي و پايين و باالي يك فاصله اطمينان %95 براي اختالف اين دو ميانگين يعني µ µ- 2 آمده است در اين فاصله : µ اگر هر دو كران فاصله مثبت باشند اين به آن معني است كه با %95 اطمينان يعني >µ 2 است µ -µ 2 است >0 ) H : µ و بنابر اين فرضيه H 0 : µ µ= 2 رد شده و به جاي آن فرضيه µ< 2 پذيرفته مي شود. µ < µ 2 µ - µ 2 >0 اگر هر دو كران فاصله منفي باشد اين به آن معنا است كه با %95 اطمينان است. يعني )2 H : µ < µ 2 است و بنابرا ين فرضيه µ µ= 2 رد شده و به جاي آن فرضيه پذيرفته مي شود. H 0 : 3( اگر كران پايين فاصله منفي و كران باالي آن مثبت باشد يعني صفر در اين فاصله قرار گيرد اين به آن معني است كه با %95 اطمينان =0 2 µ =µ است. يعني µ =µ 2 و بنابر اين فرضيه H 0 :µ =µ 2 پذيرفته مي شود. 54
55 در اين مثال همانطور كه مشاهده مي شود هر دو كران فاصله مثبت است و بنابر اين فرض صفر مبني بر يكسان بودن ميانگين H : µ > µ 2 هاي اين دو جمعيت رد شده و به جاي آن فرضيه پذيرفته مي شود. يعني ميانگين نمره رياضي دانش آموزان دختر به طور معني داري بيشتر از ميانگين نمره رياضي دانش آموزان پسر است. از طرفي چون كران پايين اين فاصله 3/3 و %95 4/3 كران باالي آن تقريبا است. لذا با اطمينان مي توان نتيجه گرفت كه اختالف ميانگين نمره رياضي دخترها و پسرها حداقل 3/3 و حداكثر 4/3 است يا به عبارت ديگر با %95 اطمينان ميانگين نمره رياضي دخترها حداقل 3/3 و حداكثر 4/3 از ميانگين نمره رياضي پسرها بيشتر است. تمرين ميانگين نمرات دروس مختلف دانش آموزان را در گروههاي ( دختر-پسر( ( شمال-جنوب( ( دختر شمال- دختر جنوب( ( پسر شمال-پسر جنوب( ( دختر شمال-پسر شمال( ( دختر جنوب-پسر جنوب( با يكديگر مقايسه كرده و در هر حالتي نتيجه به دست آمده را به طور كامل تشريح و تفسير كنيد. آزمون تساوی دو میانگین در نمونه های همبسته )جفت شده زوج شده طرح پیش آزمون-پس آزمون( : در آزمون قبل ميانگين هاي دو جمعيت از طريق دو نمونة تصادفي مستقل از هم از آن دو جمعيت با يكديگر مقايسه شدند. اما اگر بخواهيم ميانگين هاي دو جمعيت را از طريق دو نمونه وابسته از آن دو جمعيت مورد بررسي و آزمون قرار دهيم از آزمون قبل نمي توان استفاده كرد. بطور خالصه وقتي كه نمونه ها همبسته است از آزمون قبل نمي توان استفاده نمود. 55
56 منظور از دو نمونه همبسته نمونه هايي است كه در آن اعضاي دو نمونه از لحاظ فيزيكي يكي هستند و روي هر فرد نمونه دو ويژگي اندازه گيري شده است.. به خصوص از اين آزمون براي بررسي تاثير يك متغير مستقل يا آزمايشي بر روي يك متغير وابسته استفاده مي شود. همچنين از اين آزمون در طرحهاي پيش آزمون پس آزمون استفاده مي شود. فرض كنيد بخواهيم تاثير يك برنامه تمريني خاص را در بهبود انعطاف پذيري دانش آموزان مورد بررسي قرار دهيم. در مثال اين صورت يك نمونة تصادفي از دانش آموزان را انتخاب كرده و ميزان انعطاف پذيري آنان را اندازه گيري مي كنيم سپس برنامه تمريني را اجرا كرده و پس از آن مجددا انعطاف پذيري اين دانش آموزان را اندازه گيري مي كنيم. در چنين صورتي دو نمونه داريم كه اعضاي اين دو نمونه از لحاظ فيزيكي يكي هستند. يكي از اين نمونه ها ميزان انعطاف پذيري قبل از برنامه تمريني و ديگري ميزان انعطاف پذيري پس از برنامه تمريني است. اين دو نمونه را نمونه هاي همبسته يا وابسته مي گويند. البته در بسياري از موارد عمال امكان اينكه بتوان هر دو اندازه گيري را روي يك نمونه بكار برد نيست. در چنين مواردي از نمونه هاي جفت شده يا زوج شده استفاده مي شود. مثال فرض كنيد بخواهيم تاثير دو برنامه تمريني مختلف بر روي انعطاف پذيري دانش آموزان را مورد بررسي قرار دهيم. در اينصورت از لحاظ تئوري بايد يك نمونة تصادفي انتخاب كرده و هر دو برنامة تمريني را بر روي اين نمونه پياده كرده و سپس نتايج را با يكديگر مقايسه كرد. اما واضح است كه عمال امكان اينكه بتوان هر دو نوع اندازه گيري را روي يك نمونه بكار برد نيست. چون برنامة تمريني اول بر روي نتيجة برنامه دوم اثر مي گذارد. در چنين مواردي از نمونه هاي جفت شده يا زوج شده استفاده مي كنيم. بدين ترتيب كه دو نفر دانش آموز كه از نظر ويژگي هاي اثر گذار در انعطاف پذيري شبيه يكديگر هستند را انتخاب كنيد )جنسيت يكسان سن يكسان و... ) و اين دو نفر را يك جفت يا يك زوج مي ناميم. سپس يكي از آنها را در برنامه تمريني «الف» و ديگري را در برنامة تمريني» ب» قرار مي دهيم اين عمل زوج يابي را آنقدر تكرار مي كنيم تا نمونه نهايي تكميل گردد. چنين نمونه هايي را نمونه هاي جفت شده يا زوج شده مي ناميم. كه نمونه هاي جفت شده نيز نمونه هاي همبسته هستند. µ 2 فرض كنيد µ و ميانگين هاي دو جمعيت باشند و مي خواهيم اين ميانگين ها را از طريق دو نمونة همبسته از آن دو جمعيت با يكديگر مقايسه كنيم يعني مي خواهيم فرضيه H 0 : µ = µ 2 بدين منظور از مسير زير استفاده مي كنيم: را از طريق دو نمونه همبسته مورد آزمون قرار دهيم 56
57 مثال فرض كنيم بخواهيم ميانگين نمره رياضي و علوم دانش آموزان را با يكديگر مقايسه كنيم يعني مي خواهيم فرضيه به و كه در آن µ 2 ترتيب بيانگر ميانگين نمره رياضي و علوم دانش آموزان است را آزمون كنيم. بدين µ H 0 : µ = µ 2 منظور پس از رفتن به مسير فوق متغير مربوط به نمرات دروس رياضي و علوم را به عنوان يك جفت به قسمت Parled برده و فرمان را اجرا مي كنيم. پس از اجراي اين فرمان نتيجه در قالب سه جدول و در خروجي خواهد آمد. اولين Variable جدول گزارشي از برخي شاخص هاي آماري نمرات دروس رياضي و علوم دانش آموزان است. جدول دوم ضريب همبستگي بين نمرات دروس رياضي و علوم كه راجع به ضريب همبستگي بعدا و بطور مفصل بحث خواهد شد. سومين جدول نتيجه انجام آزمون فرضيه فوق است. جداول اول و سوم در زير آمده است. متذكر مي شويم كه در حالت معمولي جدول دوم در خروجي به صورت سطري )افقي( نشان داده خواهد شد كه به جهت كمبود جا در اينجا جاي سطرها و ستونهاي آن عوض شده و به صورت ستوني )عمودي( نشان داده شده است. Paired Samples Statistics Mean N Std. Deviation Std. Error Mean Pair MATH SCEIN Paired Samples Test Pair MATH. - SCEIN. Paired Differences Mean Std. Deviation Std. Error Mean % Confidence Interval of Lower the Difference Upper T Df 306 Sig. (2-tailed)
58 در اين جدول سطرهاي اول دوم و سوم به ترتيب ميانگين انحراف معيار و خطاي استاندارد ميانگين اختالف هر زوج داده است. در قسمت دوم جدول سطرهاي اول و دوم جدول با عناوين به ترتيب آماره df و t t و درجه آزادي آن است. آخرين سطر اين P.Value ي جدول با عنوان Sig. (2-tailed) همان اين آزمون است كه در اين مثال همانطور كه مشاهده مي شود P.Value خيلي كوچك بوده و دست كم تا سه رقم اعشاري صفر است. بنابر اين فرض صفر مبني بر يكسان بودن ميانگين هاي اين دو جمعيت در سطح خطاي 0/0 )و در نتيجه در سطح خطاي 0/05( رد مي شود. دو آخر در قسمت اول اين جدول با عناوين Lower و Upper به ترتيب كران هاي پايين و باالي يك فاصله اطمينان %95 براي اختالف اين دو ميانگين يعني µ - µ 2 است كه در اين مثال كران هاي فاصله منفي است. بنابراين فرضيه H 0 : µ = µ 2 رد شده و به جاي آن فرضيه H : µ < µ 2 پذيرفته مي شود. يعني ميانگين رياضي دانش آموزان بطور معني 0/7 0/26 داري كمتر از ميانگين نمره علوم آن ها است و با %95 اطمينان اختالف اين دو ميانگين حداقل و حداكثر مي باشد. تمرين ميانگين نمرات دروس مختلف را دو به دو با يكديگر مقايسه كنيد. اين عمل را يكبار روي كل نمونه يكبار به تفكيك جنسيت يكبار به تفكيك منطقه يكبار به تفكيك جنسيت و منطقه و يكبار به تفكيك جنسيت و منطقه و پايه تحصيلي انجام دهيد. تحلیل واريانس يا آنالیز واريانس يک طرفه همانطور كه از قبل مي دانيم براي مقايسه ميانگين هاي دو جمعيت از طريق دو نمونه تصادفي مستقل از هم از آن دو جمعيت از آزمون دو نمونه اي استفاده مي كنيم. اما اگر تعداد جمعيت ها از دو تا بيشتر شود يك روش آن است كه اين جمعيت ها را T توسط همان آزمون t و به صورت دو به دو با يكديگر مقايسه كرد كه در چنين صورتي براي مقايسه k جمعيت به صورت دو به t دو با يكديگر بايد تعداد ) ( آزمون انجام داد. مثال اگر بخواهيم سه جمعيت را به صورت دو به دو با يكديگر 58
59 مقايسه كنيم در اين صورت بايد تعداد ) ( بار از آزمون t استفاده كنيم و اگر اين جمعيت ها چهار تا شود براي مقايسه دو به دوي آنها بايد تعداد ) ( t آزمون انجام داد. چنين عملي باعث افزايش خطاي نوع اول مي شود. فرض كنيد بخواهيم ميانگينهاي k جمعيت را به صورت دو به با يكديگر مقايسه كنيم. در اينصورت تعداد ( ) آزمون بايد انجام دهيم. اگر خطاي نوع اول در هر آزمون را α قرار دهيم خطاي نوع اول كل اين آزمونها خواهد شد كه در آن n تعداد كل آزمونهاي انجام شده يعني همان ( ) است. اين عدد كمي كمتر از k برابر α بوده و بنابر اين خطاي نوع اول كل اين آزمونها به شدت افزايش مي يابد. مثال فرض كنيد بخواهيم ميانگينهاي سه جمعيت را به صورت دو به با يكديگر مقايسه كنيم و نيز فرض كنيد خطاي نوع اول براي هر آزمون را 0405 تعيين كنيم. چون بايد تعداد سه آزمون انجام دهيم خطاي نوع اول كل اين آزمونها خواهد شد يعني كمي كمتر از سه برابر خطاي نوع اول در هر آزمون. به طور مشابه اگر بخواهيم ميانگينهاي چهار جمعيت را به صورت دو به دو با يكديگر مقايسه كنيم و نيز فرض كنيد ( ) خطاي نوع اول براي هر آزمون را 0405 تعيين كنيم. چون بايد تعداد آزمون انجام دهيم خطاي نوع اول كل اين آزمونها به جهت ثابت نگاه خواهد شد يعني كمي كمتر از 6 برابر خطاي نوع اول در هر آزمون. به همين دليل و داشتن ميزان خطا روش ديگري با نام تحليل واريانس يكطرفه ابداع شد كه مطابق اين روش ميانگين هاي بيش از دو جمعيت نه به صورت دو به دو بلكه به صورت توام با يكديگر مقايسه مي شوند و لذا خطاي نوع اول افزايش نيافته بلكه در همان سطح α ثابت مي ماند. بنابراين تحليل واريانس يكطرفه در واقع شكل تعميم يافته آزمون مقايسه دو ميانگين است كه در آن ميانگينهاي بيش از دو جمعيت به صورت توام با يكديگر مقايسه مي شوند. فرض كنيد ميانگين هاي K جمعيت نرمال باشد. فرضيه مورد آزمون به صورت زير است. H 0: µ = µ 2 =. = µ K و فرض مقابل به صورت زير است ميانگين هاي دست كم 2 جمعيت نابرابرند : H براي انجام اين آزمون از مسير زير استفاده مي كنيم. 59
60 مثال فرض كنيد بخواهيم ميانگين نمره رياضي دانش آموزان پايه هاي اول دوم و سوم را با يكديگر مقايسه كنيم. يعني در واقع مي خواهيم فرضيه H 0 : µ = µ 2 = µ 3 كه در آن µ و µ 2 µ 3 به ترتيب بيانگر ميانگين نمرة رياضي دانش آموزان پايه هاي اول دوم و سوم است را آزمون كنيم. بدين منظور پس از رفتن به مسير فوق متغير مربوط به نمره رياضي دانش factor آموزان ( 4 )X را به قسمت Dependent List برده و متغير مربوط به پايه تحصيلي دانش آموزان را به قسمت X 3 مي بريم. پس از اجراي اين فرمان نتيجه در قالب جدولي با نام ANOVA در خروجي داده خواهد شد كه اين جدول در زير آمده است. MATH. ANOVA Sum of Squares df Mean Square F Sig. Between Groups Within Groups Total Sum of Square در اين جدول دومين ستون با عنوان مجموع مربعات يا همان SSها است. رديف اول مجموع مربعات بين گروهها يا همان اثر عامل )SSTr( رديف دوم مجموع مربعات داخل گروهها يا همان اثر خطا )SSE( و آخرين رديف نيز مجموع مربعات كل )SST( است. سومين ستون با عنوان df درجه آزادي ستون بعدي ميانگين مربعات يا همان MS ها ستون بعدي با F عنوان آماره آزمون يا همان كسر F و آخرين ستون با عنوان نيز همان P.Value ي اين آزمون است. در اين مثال همانطور Sig كه مشاهده مي شود P.Value اين آزمون 0/26 بوده كه چون از 0/05 بزرگتر است اين فرضيه در سطح خطاي ( 0/05 و در نتيجه در سطح خطاي ) 0/0 پذيرفته مي شود. يعني تفاوت معني داري بين ميانگين نمره رياضي دانش آموزان پايه هاي اول دوم و سوم وجود ندارد. براي مشاهده اين ميانگينها مي توان در همان مسير و در پنجره One-Way ANOVA روي گزينه كليك كرده و در پنجره باز شده گزينه Descriptive را عالمت زد كه در چنين صورتي عالوه بر انجام اين آزمون Options شاخصهاي ميانگين و انحراف معيار اين متغير در هر گروه نيز در خروجي داده خواهد شد. آزمون های تعقیبی )مقايسه های پس از تجزيه( در آناليز واريانس يكطرفه اگر فرض صفر پذيرفته شود)مانند مثال قبل( به معناي آن است كه تفاوت معني داري بين ميانگين ها برقرار نيست و بنابر اين آزمون خاتمه يافته است. اما اگر فرض صفر رد شود به معناي آن است كه ميانگين در دست كم دو 60
61 جمعيت نا برابر است و بنابر اين آزمون خاتمه نيافته است چون مي خواهيم ببينيم ميانگين هاي كدام جمعيت ها متفاوت از يكديگر است. به همين منظور آزمون هايي با نام آزمون های تعقیبی وجود دارد كه تعداد اين آزمون ها خيلي زياد بوده و برخي از آنها در شرايط خاص نسبت به برخي ديگر ارجحيت دارند. اما متداول ترين اين آزمون ها آزمون هاي است. شفه و توکی آزمون توكي داراي توان بيشتري نسبت به آزمون شفه است. اما استفاده از اين آزمون مستلزم برقرار بودن فرض نرمال بودن توزيع داده ها و نيز يكسان بودن حجم نمونه در گروهها است. يعني در استفاده از اين آزمون توزيع داده ها حتما بايد نرمال باشد و نيز حجم نمونه در گروه هاي مختلف بايد يكسان باشد. اما آزمون شفه نسبت به فرض نرمال بودن توزيع داده ها كمتر حساس بوده و استفاده از آن نيز مستلزم يكسان بودن حجم نمونه در گروه هاي مختلف نيست و لذا كاربرد اين آزمون از آزمون توكي Post Hoc ANOVA ANOVA بيشتر است. مسير انجام آزمون هاي تعقيبي همان مسير است. در پنجره بر روي گزينة كليك كرده و در پنجرة ظاهر شده آزمون تعقيبي مورد نظر را انتخاب مي كنيم. مثال فرض كنيد بخواهيم ميانگين نمرات درس حرفه و فن دانش آموزان پايه هاي اول دوم و سوم را با يكديگر مقايسه كنيم. يعني در واقع مي خواهيم فرضيه H 0 : µ = µ 2 = µ 3 كه در آن µ 2 µ و µ 3 به ترتيب بيانگر ميانگين نمرات حرفه و فن دانش آموزان پايه هاي اول دوم و سوم است را آزمون كنيم. نتيجه انجام اين آزمون توسط ANOVA در زير آمده است. TECH. ANOVA Sum of Squares df Mean Square F Sig. Between Groups Within Groups Total در اين جدول همانطوري كه مشاهده مي شود P.Value اين آزمون 0/05 بوده و بر اين اساس فرض صفر در سطح خطاي %5 رد مي شود. يعني ميانگين نمرات حرفه و فن دست كم در دو پايه تحصيلي متفاوت است. حال براي تعيين اينكه ميانگين كداميك از پايه ها متفاوت از يكديگر است از آزمون تعقيبي شفه استفاده مي كنيم. بدين منظور در پنجره ANOVA بر روي گزينه Post Hoc كليك كرده و در پنجره ظاهر شده آزمون تعقيبي شفه )Scheffe( را انتخاب مي كنيم. پس از اجراي اين فرمان 6
62 ابتدا ANOVA انجام شده و جدول آن در خروجي خواهد آمد. سپس آزمون تعقيبي شفه انجام مي گيرد و نتيجه آن در قالب دو جدول در خروجي خواهد آمد كه دومين جدول آن در زير آمده است. TECH. Scheffe a,b Subset for alpha = 0.05 GRADE N 2 FIRST SECOND THIRD Sig مطابق اين جدول پايه هاي اول دوم و سوم از لحاظ درس حرفه و فن در دو گروه و 2 افراز شده اند. در گروه پايه هاي اول و دوم قرار گرفته و در گروه 2 پايه هاي دوم و سوم قرار گرفته اند. اين به آن معني است كه ميانگين نمره درس حرفه و فن در پايه هاي اول و دوم تفاوت معني داري با يكديگر نداشته و آنها را مي توان در يك گروه قرار داد. پايه هاي دوم و سوم نيز تفاوت معني داري با يكديگر نداشته و آنها را نيز مي توان در يك گروه ديگر و متفاوت از گروه قبل قرار داد. يعني پايه دوم هم مي تواند در گروه قرار گيرد و هم مي تواند در گروه 2 قرار گيرد و بر اين اساس پايه دوم نه با پايه اول و نه با پايه سوم تفاوت معني داري ندارد بلكه اين تفاوت در مورد پايه هاي اول و سوم است. توجه كنيد كه نتيجه اين آزمون به هر شكلي مي تواند باشد. ممكن است هر كدام از پايه ها به تنهائي در يك گروه قرار گيرند كه در چنين صورتي ميانگين در همه پايه ها متفاوت از يكديگر خواهد بود. ممكن است دو پايه در يك گروه و پايه اي ديگر در يك گروه مجزا قرار گيرد و ممكن است پايه اي در برخي گروهها مشترك باشد مانند آنچه كه در اين مثال اتفاق افتاد. هر كدام از اين حالتها تفسير خاص خودش را دارد. تمرين ميانگين نمرات دروس مختلف را در پايه هاي اول دوم و سوم توسط ANOVA با يكديگر مقايسه كنيد و در صورت معني دار بودن تفاوت بين آنها توسط آزمون تعقيبي شفه مشخص كنيد كه كداميك از پايه ها متفاوت از يكديگرند. اين عمل را يكبار روي كل نمونه يكبار به تفكيك جنسيت يكبار به تفكيك منطقه و يكبار نيز به تفكيك جنسيت و منطقه انجام دهيد. 62
63 نحوه Recode كردن متغيرها در برخي موارد ممكن است بخواهيم مقادير يك متغير را به مقادير جديدي تغيير دهيم. بخصوص ممكن است بخواهيم يك متغير كمي كه در سطح اندازه گيري الاقل فاصله اي است را توسط كدگذاري به يك متغير ترتيبي تبديل كنيم. مثال فرض كنيد متغير وزن را به صورت كمي اندازه گيري كرده ايم اما مي خواهيم وزن را به صورت طبقه اي كمتر از و به باال تبديل كنيم. در صورتي كه بخواهيم متغير جديد روي متغير قبلي تشكيل شده و متغير قبلي از بين برود از فرمان Recode كردن در مسير زير استفاده مي كنيم. Recode into same variable Transform اما اگر بخواهيم متغير قبلي حفظ شده و متغير جديدي تشكيل شود از فرمان زير استفاده مي كنيم. Recode into different variable Transform مثال فرض كنيد در فايل test 2 بخواهيم نمرات درس رياضي دانش آموزان را به صورت زير طبقه بندي كنيم. { كه در آن x نمرات درس رياضي دانش آموزان در فاصله 0 تا 20 و y نمره تبديل يافته درس رياضي دانش آموزان است. Input ) x4( بدين منظور پس از رفتن به مسير فوق متغير مربوط به نمره درس رياضي دانش آموزان را به قسمت Variable برده و در بخش output variable يك نام براي متغير جديد وارد مي كنيم. )مثال y4( سپس با كليك كردن بر روي old and new values پنجره اي باز مي شود كه در سمت چپ اين پنجره مقادير قديم و يا فاصله هاي متغير قديم را وارد كرده و در بخش new variable مقادير جديد و يا كد مربوط به آن فاصله ها را وارد مي كنيم. 63
64 در قسمت old values و در قسمت range فاصله بين هر گروه را وارد كرده و سپس در قسمت new values كد هر گروه را وارد كرده و add را مي زنيم. تمرین : نمرات دروس مختلف دانش آموزان را مطابق با تقسيم بندي فوق طبقه بندي كرده و كد مربوط به مقادير جديد را در متغيرهاي به ترتيب Y4 Y3 Y2 Y قرار دهيد. تمرین: با استفاده از فرمان ANOVA ميانگين نمره درس علوم دانش آموزاني كه در درس رياضي خيلي ضعيف ضعيف متوسط پائين متوسط باال خوب و خيلي خوب است ( مقادير مختلف متغير Y ) را با يكديگر مقايسه كرده و در صورت معني دار بودن اختالف بين اين ميانگينها توسط آزمون شفه مشخص كنيد ميانگين كداميك از گروهها با يكديگر متفاوت است. چه نتيجه اي به دست مي آيد اين مقايسه را براي نمرات ساير دروس نيز انجام دهيد. تشکيل یک متغير جدید توسط تركيبي از متغيرهاي قدیم در مواردي ممكن است بخواهيم توسط تركيبي از متغيرهاي موجود در فايل يك متغير جديدي را ايجاد كنيم. مثال ممكن است بخواهيم تعدادي از متغيرهاي موجود در فايل را با يكديگر جمع كرده و حاصل جمع آنها را در يك متغير جديد قرار دهيم. يا مثال فرض كنيد بخواهيم ميانگين مقادير تعدادي از متغيرها را محاسبه كرده و اين ميانگينها را در يك متغير جديد قرار دهيم. در اين صورت از فرمان Compute variable در مسير زير استفاده مي كنيم. Transform Compute variable مثال فرض كنيد در در فايل test 2 بخواهيم معدل نمرات دروس مختلف هر دانش آموز را محاسبه كرده و آنها را در متغيري با نام Ave قرار دهيم در اين صورت پس از رفتن به مسير فوق در قسمت Target variable اسم متغير جديد )Ave( را وارد 64
65 كرده و در قسمت numeric expresion عبارت مورد نظر با همان فرمول محاسبه ميانگين نمرات دروس مختلف [5/) (] X4+X5+X6+X7+X8 را وارد مي كنيم. در چنين صورتي ميانگين نمرات دروس مختلف براي هر دانش آموز محاسبه شده و اين ميانگينها در متغير جديد Ave قرار مي گيرد. البته در انجام اين محاسبه اگر مقدار يكي از متغيرها براي يك نفر از افراد نمونه Missing باشد براي آن شخص محاسبه اي انجام نمي گيرد. در اين فايل نيز چون دانش آموزان كالس اول فاقد نمره زبان هستند لذا براي آنها محاسبه اي انجام نگرفته است. اما واضح است كه مايليم براي اين دانش آموزان نيز معدل دروسشان محاسبه شود منتها بدون در نظر گرفتن نمره زبان. يعني در واقع براي كالس اولي ها مي خواهيم معدل دروس توسط فرمول Ave=(X4+X5+X6+X8)/4 محاسبه شود. بدين منظور مجددا اين فرمان را اجرا مي كنيم منتها از فرمول فوق استفاده كرده و توسط گزينه If در پائين اين پنجره مشخص مي كنيم كه اين فرمان فقط براي كالس اولي ها محاسبه شود. نتيجه اجراي اين فرمان را نيز در همان متغير Ave قرار مي دهيم. 65
66 ضرايب همبستگی: در اين بحث ميخواهيم رابطه بين متغيرها را توسط شاخصي با نام ضريب همبستگي مورد بررسي قرار براي محاسبه دهيم. ميزان رابطه و همبستگي بين متغيرها شاخص هاي مختلفي وجود دارد كه عمده ترين آنها شاخص هاي ضریب همبستگی پیرسون ضریب همبستگی تاو کندال و ضریب همبستگی رتبه ای اسپیرمن است. ضريب همبستگی پیرسون: اين ضريب شاخصي است براي اندازه گيري ميزان رابطه بين دو متغير كمي كه در سطح اندازه گيري الاقل فاصله اي هستند. به عبارت ديگر هرگاه متغيرهايي را كه مي خواهيم ميزان رابطه بين آنها را اندازه گيري كنيم هر دو كمي بوده و سطح اندازه گيري آنها الاقل فاصله اي باشد )فاصله اي يا نسبتي( و نيز توزيع آنها نرمال باشد در اين صورت از ضريب همبستگی پیرسون استفاده مي كنيم. البته اگر حجم نمونه به قدر كافي بزرگ باشد و هر دو متغير در كمي بوده و در سطح اندازه گيري الاقل فاصله اي باشند حتي در صورت عدم برقراري شرط نرمال بودن باز هم مي توان از اين شاخص استفاده كرد. مقدار اين ضريب حداقل منهاي و حداكثر است. هر چه قدر مقدار اين ضريب به نزديك تر باشد بيانگر وجود رابطه خطي و مستقيم بين دو متغير است. يعني افزايش يكي از متغيرها باعث افزايش متغير ديگر مي شود و همينطور در مورد كاهش. هر چقدر مقدار اين ضريب به ت نزديك تر باشد بيانگر وجود رابطه خطي و معكوس بين دو متغيراست يعني افزايش يكي از متغيرها باعث كاهش متغير ديگر مي شود و يا بالعكس. و هر چقدر مقدار اين ضريب به صفر نزديك تر باشد بيانگر عدم وجود رابطه خطي بين دو متغير است. پس از محاسبه ضريب همبستگي در نمونه الزم است معني دار بودن آن را آزمون كنيم كه آزمون معني دار بودن ضريب همبستگي داراي فرضيه اي به صورت زير است. H 0 : H : ضريب همبستگي محاسبه شده در نمونه معني دار نيست) بين اين دو متغير رابطه برقرار نيست( ضريب همبستگي محاسبه شده در نمونه معني دار است) بين اين دو متغير رابطه برقرار است( مانند ساير آزمونها اگر P.valueي اين آزمون از 0/05 كمتر شود فرض صفر رد شده كه بيانگر معني دار بودن رابطه بين آن دو متغير است. SPSS بطور خودكار پس از محاسبه ضريب همبستگي نمونه معني دار بودن آن را آزمون كرده و P.value ي آن را در خروجي ارائه مي دهد. 66
67 ضريب همبستگی رتبه ای اسپیرمن و ضريب همبستگی تاو کندال: اين دو ضريب نيز شاخص هايي براي اندازه گيري رابطه بين دو متغير است. با اين تفاوت كه از اين شاخص ها هنگامي استفاده مي شود كه دست كم يكي از متغيرها در سطح اندازه گيري ترتيبي باشد. به عبارت ديگر براي اندازه گيري ميزان رابطه بين دو متغير وقتي دست كم يكي از متغيرها ترتیبی است از «ضرایب همبستگی رتبه ای اسپیرمن و یا تاو کندال» استفاده مي كنيم. بنابراين هر چقدر كه البته استفاده از اسپيرمن متداولتر است. اين دو ضريب نيز مانند پيرسون حداقل و حداكثر ت است مقدار اين ضرايب به نزديكتر باشد بيانگر وجود رابطه اي مستقيم بين دو متغير است و هر چقدر به ت نزديك تر باشد بيانگر وجود رابطه اي معكوس بين دو متغير است. و هر چقدر مقدار اين ضرايب به صفر نزديك تر باشد بيانگر عدم وجود رابطه بين دو متغير است. در مورد اين دو ضريب نيز مانند پيرسون الزم است پس از محاسبه آنها در نمونه معني دار بودن آنها آزمون شود و آزمون معني دار بودن آنها مانند آزمون معني دار بودن پيرسون داراي فرضيه اي به صورت زير است. H 0 : H : ضريب همبستگي محاسبه شده در نمونه معني دار نيست) بين اين دو متغير رابطه برقرار نيست( ضريب همبستگي محاسبه شده در نمونه معني دار است) بين اين دو متغير رابطه برقرار است( SPSS بطور خودكار پس از محاسبه ضريب همبستگي نمونه معني دار بودن آن را آزمون كرده و P.value ي آن را در خروجي ارائه مي دهد. مثال اگر بخواهيم معني داري وجود دارد يا خير از تعيين كنيم كه آيا بين اندازه قد دونده ها و مسافت طي شده توسط آنها ( كه هر دو متغير كمي است( رابطه ( كه به صورت ترتيبي اول دوم و سوم است( ضريب همبستگی پیرسون استفاده مي كنيم. و اگر بخواهيم رابطه بين مقام كسب شده در مسابقه شنا با طول قد شناگر را اندازه گيري كنيم از ضريب همبستگی اسپیرمن استفاده مي كنيم. اگر بخواهيم تعيين كنيم كه آيا بين نمرات درس رياضي و نمرات درس علوم دانش آموزان رابطه اي برقرار است يا خير چون نمرات اين دو درس هر دو متغيرهاي كمي و در سطح اندازه گيري فاصله اي هستند لذا از ضريب همبستگي پيرسون استفاده مي كنيم. اما اگر بخواهيم رابطه بين ميزان عالقه دانشجو به رشته تحصيلي اش و نمره درس آمار او را تعيين كنيم و ميزان عالقه به رشته نيز به صورت "خيلي كم" "كم" " متوسط" "زياد" و "خيلي زياد" اندازه گيري شده باشد چون يكي از اين متغيرها به صورت ترتيبي و ديگري به صورت فاصله اي اندازه گيري شده اند لذا از ضريب همبستگي اسپيرمن استفاده مي كنيم. 67
68 همچنين اگر بخواهيم رابطه بين ميزان عالقه دانشجو به رشته تحصيلي اش و ميزان عالقه او به درس آمار را اندازه گيري كنيم و ميزان عالقه دانشجو به رشته تحصيلي اش و نيز ميزان عالقه به درس آمار به صورت ترتيبي "خيلي كم" "كم" "متوسط" و... اندازه گيري شده باشد چون هر دو متغير در سطح اندازه گيري شده اند از ضريب همبستگي اسپيرمن استفاده مي كنيم. مسير محاسبه ضرایب همبستگي در SPSS به صورت زیر است. مثال فرض كنيد بخواهيم ضريب همبستگي بين نمرات دروس مختلف را محاسبه كنيم. در اين صورت پس از رفتن به مسير Correlation فوق متغيرهاي مربوط به نمرات دروس را به قسمت Variables مي بريم. در قسمت پايين و در بخش مشخص مي كنيم كه كداميك از اين ضرايب را مي خواهيم محاسبه كنيم. در اين مثال چون نمرات دروس Coefficientes متغيرهاي كمي و در سطح اندازه گيري فاصله اي است از ضريب همبستگي پيرسون كه پيش فرض SPSS نيز پيرسون است استفاده مي كنيم. نتيجه به صورت يك ماتريس متقارن با نام ماتريس همبستگي در خروجي خواهد آمد كه اين ماتريس در زير آمده است. Correlations MATH. SCEIN. TECH. FOREI. PERSIAN MATH. Pearson Correlation.776 **.75 **.790 **.678 ** Sig. (2-tailed) N SCEIN. Pearson Correlation.776 **.756 **.778 **.648 ** Sig. (2-tailed) N TECH. Pearson Correlation.75 **.756 **.709 **.63 ** Sig. (2-tailed) N FOREI. Pearson Correlation.790 **.778 **.709 **.729 ** Sig. (2-tailed) N PERSIAN Pearson Correlation.678 **.648 **.63 **.729 ** Sig. (2-tailed) N
69 Correlations MATH. SCEIN. TECH. FOREI. PERSIAN MATH. Pearson Correlation.776 **.75 **.790 **.678 ** Sig. (2-tailed) N SCEIN. Pearson Correlation.776 **.756 **.778 **.648 ** Sig. (2-tailed) N TECH. Pearson Correlation.75 **.756 **.709 **.63 ** Sig. (2-tailed) N FOREI. Pearson Correlation.790 **.778 **.709 **.729 ** Sig. (2-tailed) N PERSIAN Pearson Correlation.678 **.648 **.63 **.729 ** Sig. (2-tailed) N **. Correlation is significant at the 0.0 level (2-tailed). در جدول فوق كه در واقع ماتريس همبستگي نمرات دروس مختلف است در هركدام از خانه هاي اين جدول ضريب همبستگي پيرسون بين نمرات دو درس P-valueي آزمون معني دار بودن اين ضريب و نيز حجم نمونه آمده است. همانطوريكه مشاهده مي شود عناصر قطر اصلي اين ماتريس همگي يك بوده و P-value براي آن محاسبه نشده است. چون عناصر قطر اصلي در واقع ضريب همبستگي يك متغير با خودش است. همچنين اين ماتريس متقارن است يعني مثال خانه سطر دوم ستون سوم آن با خانه سطر سوم ستون دوم آن يكي است. چون ضريب همبستگي نسبت به دو متغيرش متقارن است. به عبارت ديگر ضريب y و x همبستگي برابر است با ضريب همبستگي. و y x مطابق اين جدول مشاهده مي شود كه مثال ضريب همبستگي بين نمرات دروس رياضي و علوم دانش آموزان 0/776 بوده و p-valueي آزمون معني دار بودن اين ضريب تا سه رقم اعشار صفر است. بنابر اين اين ضريب در سطح خطاي ( 0/0 و در نتيجه در سطح خطاي 0/05( معني دار است. چون مقدار اين ضريب مثبت است مي توان نتيجه گرفت كه رابطه اي مستقيم و معني دار بين نمرات دروس رياضي و علوم دانش آموزان برقرار است. با توجه به اعداد اين جدول اين نتيجه در مورد ساير دروس نيز برقرار است ( همانطوريكه انتظار داشتيم(. همچنين مطابق اطالعات سطر اول اين جدول مي توان نتيجه گرفت كه بيشترين 69
70 همبستگي نمرات درس رياضي با نمرات درس زبان و پس از آن با نمرات درس علوم است. پس از آن نيز نمرات دروس حرفه و فن و فارسي قرار مي گيرد. به همين ترتيب در مورد ساير دروس نيز مي توان نتايجي مشابه به دست آورد. ضریب همبستگي جزئي ( )Partial Correlation از اين شاخص براي محاسبه همبستگي بين دو متغير پس از حذف اثر يك يا بيش از يك متغير استفاده مي شود. گاهي اوقات به نظر مي رسد بين دو متغير رابطه معني داري وجود دارد حال آنكه وجود رابطه بين آن دو متغير متاثر از وجود يك يا بيش از يك متغير ديگر است كه اگر اثر آن متغيرها حذف شود ممكن است بين آن دو متغير رابطه معني داري وجود نداشته باشد. در چنين مواردي و براي محاسبه همبستگي بين دو متغير پس از حذف اثر يك يا بيش از يك متغير از ضريب همبستگي جزئي استفاده مي شود كه مسير آن در SPSS به صورت زير است. Analyze Correlate Partial مثال ( مثال صفحه 44 از كتاب تحليل رگرسيون خطي( داده هاي زير "تعداد گلهاي زده شده" " ميزان فروش چتر" و " ميزان بارندگي" در يكي از ميادين فوتبال را در دوازده مسابقه برگزار شده در آن استاديوم و در يك فاصله زماني مشخص نشان مي دهد. تعداد گلهاي زده شده ميزان فروش چتر ميزان بارندگي
71 ضريب همبستگي بين "تعداد گلهاي زده شده" و "ميزان فروش چتر" و نيز ضريب همبستگي بين اين دو متغير پس از حذف اثر " ميزان بارندگي" را محاسبه كرده و نتيجه گيري كنيد. حل: ابتدا توسط فرمان Bivariate ضريب همبستگي بين اين دو متغير را به دست مي آوريم. نتيجه در جدول زير آمده است. Correlations Goal Umberela Goal Pearson Correlation * Sig. (2-tailed).026 N 2 2 Umberela Pearson Correlation * Sig. (2-tailed).026 N 2 2 *. Correlation is significant at the 0.05 level (2-tailed). همانطوريكه مشاهده مي شود ضريب همبستگي بين اين دو متغير و p-valueي معني دار بودن اين ضريب است كه بيانگر وجود رابطه اي معكوس و معني دار ( در سطح خطاي 0405( بين اين دو متغير است. يعني مطابق با اين ضريب نتيجه مي شود كه اگر در يك روز چتر بيشتري فروخته شود در آن روز گل كمتري زده خواهد شد و بر اين اساس اگر بخواهيم 7
72 در يك روز خاص بازي خيلي پر هيجان بوده و گلهاي زيادي بين دو تيم رد و بدل شود بايد در آن روز فروش چتر در اطراف استاديوم را ممنوع كنيم!!!! اما واضح است كه اين نتيجه نامعقول بوده و اساسا فروش چتر ارتباطي با گلهاي زده شده ندارد. فروش چتر مي تواند به جهت بارندگي در آن روز باشد و بر اين اساس الزم است ضريب همبستگي بين اين دو متغير پس از حذف اثر بارندگي محاسبه شود. نتيجه در زير آمده است. Correlations Control Variables Goal Umberela Rain Goal Correlation Significance (2-tailed)..826 Df 0 9 Umberela Correlation Significance (2-tailed).826. Df 9 0 p- همانطوريكه مشاهده مي شود پس از حذف اثر بارندگي ضريب همبستگي بين اين دو متغير به كاهش يافته و valueي آزمون معني دار بودن آن است كه بيانگر معني دار نبودن اين ضريب است. بنابر اين وجود همبستگي بين اين دو متغير به جهت وجود متغير "ميزان بارندگي" بود كه اگر اثر بارندگي حذف شود رابطه معني داري بين تعداد گلهاي زده شده در مسابقه و ميزان فروش چتر در آن روز وجود ندارد. ضریب همبستگي فاصله اي Correlation( )Distance اين ضريب شاخصي است براي محاسبه تشابه يا عدم تشابه ( فاصله( بين هر جفت مشاهده يا هر جفت متغير. يعني اين شاخص هم براي جفت مشاهدات و هم براي جفت متغيرها به كار مي رود. از اين شاخص به طور مستقيم استفاده نشده بلكه از آن براي استفاده در ساير تحليلها مانند تحليل عاملي آناليز خوشه اي و تحليل مميزي استفاده مي شود. 72
73 رگرسيون : در تحليل رگرسيون مي خواهيم رابطه بين يك متغير وابسته و چند متغير مستقل را توسط يك فرمول رياضي نشان دهيم. در ساده ترين حالت تعداد يك متغير وابسته و يك متغير مستقل در نظر گرفته و رابطه ي بين آنها را يك رابطه خطي به شكل در نظر مي گيريم. چنين مدلي را يك مدل خطي ساده مي نامند. در اين مدل متغير مستقل يا متغير پيشگو و متغير وابسته يا متغير پاسخ است و و ضرايب خط رگرسيون كه پارامتر هاي ثابتي هستند كه آنها را از روي يك نمونه تصادفي بر آورد مي كنيم. براي برآورد اين پارامترها از روش كمترين مربعات استفاده مي شود. ضريب زاويه يا شيب و عرض از مبدا خط رگرسيون است. پس از بر آورد اين ضرائب آنها را با يا ونيز يا نشان مي دهيم و برآورد معادله خط رگرسيون را به صورت و يا نشان مي دهيم. با داشتن چنين معادله اي و با معلوم بودن يك مقدار براي متغير مستقل مي توان يك مقدار براي متغير وابسته پيش بيني كرد كه اگر مدل معني دار باشد در اينصورت هر چقدر ضريب تعيين مدل باالتر باشد مقدار پيش بيني شده توسط اين مدل به مقدار واقعي نزديكتر خواهد بود. در حالت ايده آل و با شرط معني دار بودن مدل اگر ضريب تعيين مساوي يك باشد در اينصورت پيش بيني كه توسط اين مدل انجام مي گيرد به طور كامل ( 00 درصد( با مقدار واقعي يكسان خواهد بود. در يك مدل رگرسيون خطي ساده شيب خط بيانگر ميزان تغييرات در متغير وابسته به ازاي يك واحد تغيير در متغير مستقل است. اگر متغير مستقل داراي صفر معني دار باشد يعني بر روي عدد صفر تعريف شود در اينصورت عرض از مبدا خط بيانگر مقدار متغير وابسته به ازاي عملي خاصي ندارد. x=0 است اما اگر متغير مستقل بر روي صفر تعريف نشود در اينصورت عرض از مبدا هيچگونه تعبير پس از بر آورد معادله خط رگرسيون الزم است معني دار بودن اين معادله و نيز معني دار بودن هر كدام از اين ضرايب آزمون شود كه آزمون معني دار بودن مدل رگرسيون داراي فرضيه اي به صورت زير است. { مدل رگرسيوني برازش شده معني دار نيست مدل رگرسيوني برازش شده معني دار هست 73
74 ANOVA كه اين فرضيه توسط يك تحليل واريانس ( ) آزمون مي شود هم چنين آزمون معني دار بودن ضرايب خط رگرسيون داراي فرضيه هايي به صورت زير است. { { وجود وجود يا همان شيب خط رگرسيون در معادله معني دار نسيت يا همان شيب خط رگرسيون در معادله معني دار هست { { وجود وجود يا همان يا همان عرض از مبدا در مدل معني دار نيست عرض از مبدا در مدل معني دار هست كه اين آزمون ها توسط آماره t صورت مي گيرد. ضریب تعيين ( ضریب تشخيص( نسبت پراكندگي بيان شده توسط مدل رگرسيون به پراكندگي كل را ضريب تعيين يا ضريب تشخيص گفته و آنرا با 2 R- ( R )square نشان مي دهيم. ضريب تعيين مشخص مي كند كه چه نسبتي از تغييرات يا پراكندگي در متغير وابسته مطابق با مدل رگرسيوني به دست آمده به متغير مستقل مربوط است يا به عبارت ديگر متغير مستقل چه نسبتي از تغييرات متغير وابسته را % تبيين مي كند. مثال اگر در يك مدل رگرسيوني ضريب تعيين بدست آمده باشد اين به آن معني است كه از تغييرات يا پراكندگي در متغير وابسته توسط اين مدل رگرسيوني به متغير مستقل مربوط مي شود و % باقي مانده به ساير متغيرها بستگي دارد كه در اين مدل ناديده گرفته شده است. مقدار اين ضريب حداقل صفر و حداكثر است. هر چقدر مقدار اين ضريب به صفر نزديكتر باشد بيانگر نا معتبر بودن مدل رگرسيون و هر چقدر مقدار آن به يك نزديكتر باشد بيانگر معتبر بودن مدل است. در رگرسيون خطي ساده ضريب تعيين برابر است با مجذور ضريب همبستگي. مسير انجام تحليل رگرسيون ساده )با یک متغير مستقل( به صورت زیر است: مثال در فايل فرض كنيد نمرات درس علوم تابعي از نمرات درس رياضي باشد يعني نمرات درس علوم متغير وابسته و نمرات درس رياضي متغير مستقل باشد. براي برازش يك مدل رگرسيوني به اين دو متغير به مسير فوق رفته و در پنجره ظاهر شده متغير وابسته يا همان نمرات درس علوم را به قسمت و متغير مستقل يا نمرات درس رياضي را به قسمت 74
75 مي بريم. در قسمت سمت راست اين پنجره مي توان تعيين كرد كه اين مدل با وجود عرض از مبدا يا بدون وجود آن باشد و اكيدا توصيه مي شود كه همواره هر مدل رگرسيوني را با وجود عرض از مبدا بدست آوريم مگر آنكه داليل كافي براي عدم وجود عرض از مبدا وجود داشته باشد. در قسمت پايين اين پنجره و در بخش Models مي توان تعيين كرد كه مدل برازش شده يك مدل خطي) Linear ( يا مدل غير خطي باشد و در قسمت انتهايي اين پنجره مي توان مشخص كرد كه جدول ANOVA مربوط به آزمون معني دار بودن مدل رگرسيون نيز در خروجي داده شود. پس از اجراي اين فرمان نتيجه در قالب سه جدول اصلي و در خروجي خواهد آمد كه اين جداول در زيرآمده است. Model Summary Adjusted R Std. Error of the R R Square Square Estimate The independent variable is MATH.. ANOVA Sum of Squares df Mean Square F Sig. Regression Residual Total The independent variable is MATH.. Coefficients Unstandardized Coefficients Standardized Coefficients B Std. Error Beta t Sig. MATH (Constant) در اولين جدول با عنوان ستون اول با عنوان R قدر مطلق ضريب همبستگي بين اين دو متغير است كه در اين مثال مقدار اين ضريب شده است. دومين ستون با عنوان ضريب تعيين اين مدل است كه در اين مثال ضريب تعيين 2 شده است و مي توان نتيجه گرفت كه حدود % 2 از تغييرات يا پراكندگي در نمرات درس علوم دانش آموزان مطابق با اين مدل رگرسيوني به نمرات درس رياضي آنان بستگي دارد. ستون بعدي با نام 75
76 ضريب تعيين تعديل شده است كه كاربرد آن در رگرسيونيهاي چند گانه بوده و بعدا راجع به آن صحبت خواهد شد. آخرين ستون اين جدول خطاي استاندارد برآورد است. خطاي استاندارد برآورد شاخصي است كه توسط آن مي توان مشخص كرد كه مقدار برآورد شده و يا پيش بيني شده متغير وابسته توسط مدل رگرسيون به طور متوسط چقدر تا مقدار واقعي فاصله دارد. جدول بعدي با نام جدول نتيجه آزمون معني دار بودن مدل رگرسيوني است كه در اين مثال اين آزمون خيلي كوچك بوده و دست كم تا سه رقم اعشار صفر است. بنابر اين فرض صفر مبني بر معني دار نبودن مدل رد مي شود يعني مدل رگرسيوني به دست آمده معني دار است. سومين جدول با نام برآورد ضرايب خط رگرسيون و نتيجه آزمون معني دار بودن آنهاست. در اين جدول ستون و 2 2 اول با عنوان B برآورد ضرايب رگرسيون است كه در اين مثال است. ستون دوم خطاي استاندارد اين ضرايب است. ستون بعدي با عنوان Beta ضرايب استاندارد شده است كه كاربرد آن در رگرسيونيهاي چندگانه بوده و بعدا راجع به آنها صحبت خواهد شد. ستون بعدي با عنوان t آماره آزمون معني دار بودن اين ضرايب است. آخرين ستون اين جدول با عنوان ي آزمون معني دار بودن اين ضرايب است كه در اين مثال هر دو خيلي كوچك بوده و دست كم تا سه رقم اعشار صفر است. بنابراين فرض صفر مبني بر معني دار نبودن اين ضرائب در سطح خطاي ( 040 و در نتيجه در سطح خطاي 0405( رد مي شود. بر اين اساس وجود هر كدام از اين ضرايب در مدل معني دار است. خالصه نتيجه اي كه از این تحليل بدست مي آید آن است كه: فرض كنيد y بيانگر نمره درس علوم و بيانگر نمره x درس رياضي دانش آموزان باشد. و نيز فرض كنيد نمرات درس علوم تابعي از نمرات درس رياضي باشد يعني نمرات درس علوم متغير وابسته و نمرات درس رياضي متغير مستقل باشد. در اين صورت يك مدل خطي رگرسيوني برازش شده بين اين دو متغير به صورت زير است. 2 2 كه اين مدل معني دار است و نيز وجود هر كدام از اين ضرايب در مدل معني دار است و ضريب تعيين اين مدل 2 است. يعني % 2 از تغييرات يا پراكندگي در نمرات علوم دانش آموزان مطابق با اين مدل به نمره رياضي آنها بستگي داشته و 76
77 درصد به ساير عوامل بستگي داشته كه در اين مدل ناديده گرفته شده اند. يا به عبارت ديگر حدود درصد از پراكندگي در نمرات درس علوم دانش آموزان را مي توان مطابق با اين مدل به نمرات درس رياضي آنها مربوط دانست. حال با داشتن چنين مدلي و با معلوم بودن نمره رياضي يك دانش آموز مي توان نمره درس علوم او را پيش بيني كرد. مثال فرض كنيد دانش آموزي در درس رياضي نمره بگيرد در اينصورت داريم. بنابراين اگر دانش آموزي در درس رياضي نمره بگيرد پيش بيني مي شود كه نمره علوم او حدود شود كه البته اين پيش بيني توام با ميزاني خطاست كه هر چقدر ضريب تعيين مدل باالتر باشد اين خطا كمتر است. همچنين چون خطاي استاندارد برآورد در اولين جدول بيني مي شود كه نمره علوم او حدود مي باشد لذا مي توان نتيجه گرفت كه اگر نمره رياضي يك دانش آموز باشد و نيز به طور متوسط نمره واقعي علوم اين دانش آموز حدود باشد پيش بيشتر يا كمتر از است. چون شيب خط رگرسيون حدودا. به دست آمده است اين به آن معني است كه هر يك واحد افزايش در نمره درس رياضي باعث ايجاد حدود. افزايش در نمره علوم خواهد شد. عرض از مبدا خط حدود است لذا نمره علوم دانش آموزاني كه از لحاظ رياضي خيلي ضعيف بوده و نمره آنها در حد صفر است حدود برآورد مي شود. در مسير انجام رگرسيون ساده و در پنجره Curve Estimation با كليك كردن بر روي گزينه Save در گوشه سمت راست اين پنجره مي توان مقدار پيش بيني شده متغير وابسته به ازاي هركدام از مشاهدات و نيز باقيمانده مقدار پيش بيني شده با مقدار واقعي را محاسبه كرده و به عنوان متغيرهاي جديد در فايل داده ذخيره كرد. از اين متغيرها در انجام برخي تحليلها و به خصوص تحليلهاي مربوط به آزمون پيش فرضهاي رگرسيون استفاده مي شود. مدلهاي غير خطي در مدلهاي غير خطي رابطه بين متغير مستقل با متغير وابسته به صورت يك معادله غير خطي در نظر گرفته مي شود. براي برازش مدل غير خطي به داده ها از همان مسير قبل استفاده مي كنيم. 77
78 و در قسمت نوع مدل مورد نظر را انتخاب مي كنيم. براي آگاهي از فرمول هاي اين مدل ها مي توان از كمك گرفت. مثال فرض كنيد مدل هاي خطي) Linear ( لگاريتمي) )Logarithmic درجه دو) Quadratic ) و درجه سه) Cubic ( را به متغيرهاي نمرات درس رياضي ( به عنوان متغير مستقل يا ) x و نمرات درس علوم ( به عنوان متغير وابسته يا ) y برازش كنيم. نتيجه انجام اين تحليل در زير آمده است. Linear Model Summary Adjusted R Std. Error of the R R Square Square Estimate The independent variable is MATH.. ANOVA Sum of Squares Df Mean Square F Sig. Regression Residual Total The independent variable is MATH.. Coefficients Unstandardized Coefficients Standardized Coefficients B Std. Error Beta t Sig. MATH (Constant) اين سه جدول نتيجه برازش مدل خطي به اين دو متغير است كه قبال راجع به آنها به طور مفصل بحث شد. در ادامه سه جدول زير نتيجه برازش مدل لگاريتمي به اين سه متغير آمده است. 78
79 Logarithmic Model Summary Adjusted R Std. Error of the R R Square Square Estimate The independent variable is MATH.. ANOVA Sum of Squares Df Mean Square F Sig. Regression Residual Total The independent variable is MATH.. Coefficients Unstandardized Coefficients Standardized Coefficients B Std. Error Beta t Sig. ln(math.) (Constant) در اين سه جدول نيز مانند جداول مربوط به مدل خطي در اولين جدول ضريب همبستگي ضريب تعيين و خطاي استاندارد برآورد آمده است. جدول دوم ( جدول )ANOVA نتيجه آزمون معني دار بودن مدل و سومين جدول شامل برآورد ضرائب خطاي استاندارد آنها آماره آزمون معني دار بودن اين ضرائب و نيز P-valueي اين آزمون است. مطابق اين تحليل مدل لگاريتمي برازش شده به اين دو متغير به صورت زير است. 2 آزمون معني دار بودن اين مدل در جدول تا سه رقم اعشار صفر است كه بيانگر معني دار بودن مدل در هر كدام از سطوح خطاي و است. همچنين P-valueي آزمون معني دار بودن هر كدام از ضرائب در سومين 79
80 جدول نيز تا سه رقم اعشار صفر است كه بيانگر معني دار بودن وجود هر كدام از اين ضرائب در مدل است. ضريب تعيين اين مدل ودقت برآورد است. در ادامه نتيجه برازش مدل درجه دو به اين سه متغير آمده است. Quadratic Model Summary Adjusted R Std. Error of the R R Square Square Estimate The independent variable is MATH.. ANOVA Sum of Squares df Mean Square F Sig. Regression Residual Total The independent variable is MATH.. Coefficients Unstandardized Coefficients Standardized Coefficients B Std. Error Beta t Sig. MATH MATH. ** (Constant) در اين سه جدول نيز مانند جداول مربوط به مدلهاي خطي و لگاريتمي در اولين جدول ضريب همبستگي ضريب تعيين و خطاي استاندارد برآورد آمده است. جدول دوم ( جدول )ANOVA نتيجه آزمون معني دار بودن مدل و سومين جدول شامل برآورد ضرائب خطاي استاندارد آنها آماره آزمون معني دار بودن اين ضرائب و نيز P-valueي اين آزمون است. مطابق اين تحليل مدل درجه دو برازش شده به اين دو متغير به صورت زير است. 80
81 آزمون معني دار بودن اين مدل در جدول تا سه رقم اعشار صفر است كه بيانگر معني دار بودن مدل در هر كدام از سطوح خطاي و است. همچنين P-valueي آزمون معني دار بودن ضريب ثابت و ضريب جمله درجه دو در سومين جدول تا سه رقم اعشار صفر است كه بيانگر معني دار بودن وجود هر كدام از اين ضرائب در مدل است. اما P- valueي ضريب جمله درجه اول است كه اگر سطح معني داري را در نظر بگيريم وجود اين جمله در مدل معني دار نيست اما مي توان با افزايش سطح معني داري به وجود اين جمله در مدل را نيز معني دار كرد.ضريب تعيين اين مدل و دقت برآورد آن است. در ادامه نتيجه برازش مدل درجه دو به اين سه متغير آمده است. Cubic Model Summary Adjusted R Std. Error of the R R Square Square Estimate The independent variable is MATH.. ANOVA Sum of Squares df Mean Square F Sig. Regression Residual Total The independent variable is MATH.. Coefficients Unstandardized Coefficients Standardized Coefficients B Std. Error Beta t Sig. MATH MATH. ** MATH. ** (Constant)
82 در اين سه جدول نيز مانند جداول مربوط به مدلهاي قبلي در اولين جدول ضريب همبستگي ضريب تعيين و خطاي استاندارد برآورد آمده است. جدول دوم ( جدول )ANOVA نتيجه آزمون معني دار بودن مدل و سومين جدول شامل برآورد ضرائب خطاي استاندارد آنها آماره آزمون معني دار بودن اين ضرائب و نيز P-valueي اين آزمون است. مطابق اين تحليل مدل درجه سه برازش شده به اين دو متغير به صورت زير است. در اين مدل ضريب جمله درجه سه خيلي كوچك بوده و تا سه رقم اعشار صفر است. آزمون معني دار بودن اين مدل در جدول تا سه رقم اعشار صفر است كه بيانگر معني دار بودن مدل در هر كدام از سطوح خطاي و است. اما مطابق جدول سوم و با توجه به P-valueي آزمون معني دار بودن ضرائب در مدل مي توان نتيجه گرفت كه تنها وجود ضريب ثابت در مدل معني دار بوده و وجود ساير جمالت در مدل معني دار نيست. بنا بر اين اين مدل درجه سه مدل مناسبي براي برازش به اين دو متغير نيست. ضريب تعيين اين مدل و دقت برآورد آن است. رگرسيون چندگانه در بحث رگرسيون چندگانه مي خواهيم رابطة بين يك متغير وابسته و چند متغير مستقل را توسط يك مدل رياضي نشان دهيم. در ساده ترين حالت اين مدل را به صورت خطي در نظر مي گيريم. فرض كنيد y متغير وابسته يا متغير پاسخ كه يك متغير كمي پيوسته و در سطح اندازه گيري الاقل فاصله اي ( فاصله اي يا نسبتي( است و نيز فرض كنيد متغيرهاي مستقل يا متغيرهايي پيشگو باشند كه اين متغير ها مي توانند متغيرهاي پيوسته يا متغيرهاي گسسته باشند. فرض مي كنيم متغير وابسته يك متغير تصادفي و داراي توزيع نرمال است اما متغيرهاي مستقل مي توانند متغير تصادفي و يا غير تصادفي باشند. يك مدل خطي چندگانه مدلي به شكل زير است. كه در آن ها ضرايب مدل هستند اين ضرائب كه پارامتر هاي ثابتي هستند و هدف از انجام تحليل رگرسيون برآورد اين پارامترها از روي داده هاي يك نمونه تصادفي است. پس از برآورد اين پارامترها مقدار برآورد شده آنها را با و يا با نشان مي دهيم. همچنين مدل برآورد شده را به صورت زير نشان مي دهيم. 82
83 پس از برآورد مدل الزم است معني دار بودن اين مدل و نيز معني دار بودن وجود هر كدام از اين ضرائب در مدل آزمون شود كه آزمون معني دار بودن مدل رگرسيون داراي فرضيه اي به صورت است. { مدل رگرسيون معني دار نيست مدل رگرسيون معني دار است و نيز آزمون معني دار بودن هر كدام از اين ضرايب در مدل داراي فرضيه اي به صورت زير است. { وجود وجود در مدل معني دار نيست در مدل معني دار است مسير انجام رگرسيون چندگانه در به صورت زير است. مثال فرض كنيد نمرات درس رياضي تابعي از نمرات دروس علوم حرفه و فن زبان و فارسي باشد. يعني نمرات درس رياضي متغير پاسخ) y( و نمرات دروس علوم حرفه و فن زبان و فارسي متغيرهاي پيشگو ( ) باشد. براي برازش يك مدل چندگانه به اين متغيرها پس از رفتن به مسير فوق متغير مربوط به نمرات درس رياضي را به قسمت و متغيرهاي مربوط به نمرات ساير دروس را به قسمت مي بريم. پس از اجراي اين فرمان نتيجه در قالب چند جدول و در خروجي خواهدآمد كه اين جداول در زير آمده است. Model Summary Model R R Square Adjusted R Square Std. Error of the Estimate.84 a a. Predictors: (Constant), PERSIAN, TECH., SCEIN., FOREI. 83
84 ANOVA b Model Sum of Squares df Mean Square F Sig. Regression a Residual Total a. Predictors: (Constant), PERSIAN, TECH., SCEIN., FOREI. b. Dependent Variable: MATH. Coefficients a Unstandardized Coefficients Standardized Coefficients Model B Std. Error Beta t Sig. (Constant) SCEIN TECH FOREI PERSIAN a. Dependent Variable: MATH. : در اولين جدول با عنوان ستون اول با عنوان R ضريب همبستگي چندگانه است. ضريب همبستگي چندگانه شاخصي است كه توسط آن ميزان همبستگي بين متغير وابسته و متغيرهاي مستقل به طور توام اندازه گيري مي شود. در اين مثال مقدار اين ضريب. است كه بيانگر همبستگي باال بين متغير وابسته و متغيرهاي مستقل به طور توام مي باشد.. ستون بعدي با عنوان ضريب تعيين مدل است كه در اين مثال مقدار آن حدود است و همانطوريكه از قبل مي دانيم اين به آن معني است كه % از تغييرات يا پراكندگي در نمرات درس رياضي ( متغير پاسخ( توسط نمرات اين چهار درس ( متغير هاي پيشگو( به طور توام تبيين مي شود. ضريب تعيين برابر با مجذور ضريب همبستگي چندگانه است. ستون بعدي با عنوان ضريب تعيين تعديل شده است. ضريب تعيين تعديل شده شاخص است صرفا براي مقايسه ضريب تعيين دو مدل مختلف كه داراي تعداد متغيرهاي مستقل متفاوتي هستند. به عبارت ديگر براي مقايسه 84
85 ضريب تعيين در دو مدل مختلف كه اين دو مدل داراي متغير هاي مستقل متفاوتي هستند از ضريب تعيين تعديل شده استفاده مي شود و كاربرد ديگري ندارد. آخرين ستون اين جدول نيز خطاي استاندارد بر آورد است. در اين مثال مقدار اين شاخص حدود شده است. اين به آن معني است كه مقدار پيش بيني شده متغير پاسخ توسط اين مدل به طور متوسط حدود واحد با مقدار واقعي فاصله دارد. دومين جدول با عنوان جدول جدول تحليل واريانس مربوط به آزمون معني دار بودن مدل رگرسيون است. در اين مثال اين آزمون خيلي كوچك بوده و دست كم تا سه رقم اعشار صفر است. بنابراين فرض صفر مبني بر معني دار نبودن اين مدل در سطح خطاي % ( و در نتيجه %( رد مي شود. يعني مدل معني دار است. سومين جدول با عنوان برآورد ضرايب مدل و نيز نتيجه آزمون معني دار بودن اين ضرايب است. در اين جدول 2 ستون اول به عنوان همان برآورد ضرايب مدل است كه در اين مثال داريم بنابراين برآورد مدل رگرسيون به شكل زير است. در يك مدل رگرسيون چندگانه ضريب يك متغير مشخص مي كند كه با فرض ثابت بودن ساير متغيرها هر يك واحد تغيير در. آن متغير مستقل باعث ايجاد چقدر تغيير در متغير وابسته خواهد شد. مثال در اين مثال ضريب حدودا 2 است اين به آن. ) باعث ايجاد 2 معني است كه با فرض ثابت بودن ساير متغيرها هر يك واحد افزايش در نمره درس علوم ( افزايش در نمره درس رياضي خواهد شد. اگر عالمت يك ضريب منفي باشد به معني كاهش متغير وابسته به ازاي افزايش آن متغير مستقل - بود نتيجه مي شد كه با فرض ثابت بودن ساير متغيرها هر يك واحد افزايش خواهد بود. مثال اگر ضريب عدد منفي. ) باعث ايجاد 2 در نمره درس علوم ( كاهش در نمره درس رياضي خواهد شد. دومين ستون با عنوان خطاي استاندارد اين برآورد هاست. سومين ستون با عنوان برآورد پارامترهاي استاندارد شده است. در محاسبه اين برآوردها ابتدا داده ها استاندارد شده و سپس برآورد پارامترها از روي داده هاي استاندارد شده محاسبه مي شود. از اين برآوردها براي مقايسه اثر متغيرهاي پيشگو بر متغير پاسخ با يكديگر استفاده مي شود. به عبارت ديگر براي مقايسه اثر متغير هاي مستقل بر متغير وابسته از ضرايب اين 85
86 متغيرها نمي توان استفاده كرد چون ممكن است متغيرهاي مستقل داراي واحدهاي اندازه گيري متفاوتي باشند كه اين واحدها در محاسبه ضرايب متغير مؤثر است. مثال در يك مدل رگرسيون ممكن است ضريب يكي از متغيرهاي مستقل از ساير ضرايب بزرگتر باشد حال آنكه اين متغير نسبت به ساير متغيرهاي مستقل اثر كمتري بر متغير وابسته داشته باشد. به همين دليل و به جهت حذف اثر واحد اندازه گيري داده ها در بر آورد ضرايب ابتدا داده ها را استاندارد كرده و سپس ضرايب بر آورد مي شود كه اين ضرايب استاندارد شده قابل مقايسه با يكديگر هستند. يعني اگر ضريب استاندارد شده يك متغير از ساير ضرايب بزرگتر باشد مي توان نتيجه گرفت كه آن متغير اثر بيشري بر متغير وابسته دارد. در محاسبه ضرايب استاندارد شده همواره مقدار ثابت وجود نخواهد داشت يعني برآورد مقدار ثابت استاندارد شده همواره صفر خواهد بود. در اين مثال با توجه به ضرايب استاندارد شده مي توان نتيجه گرفت كه نمره درس زبان بيشترين تأثير را بر نمره رياضي دارد و پس از آن به ترتيب نمرات دروس علوم فارسي و حرفه و فن قرار دارند. حال آنكه اگر از برآورد ضرائب غير استاندارد شده استفاده شود نتيجه مي شود كه نمره درس علوم بيشترين تاثير را بر نمره درس رياضي دارد كه اين نتيجه اشتباه است. ستون بعدي با عنوان t آماره آزمون معني دار بودن اين ضرايب در مدل است و آخرين ستون اين جدول با عنوان ي آزمون معني داري هر كدام از اين ضرايب در مدل است كه در اين مثال همانطور كه مشاهده مي شود كليه اين ها از كوچكتر بوده و بر اين اساس فرض صفر مبني بر معني دار نبودن اين ضرائب براي كليه اين ضرائب در سطح خطاي معني دار است. ( و در نتيجه در سطح خطاي ) رد مي شود. بر اين اساس وجود همة اين ضرايب در مدل به طور خالصه نتيجه اي كه از انجام اين تحليل رگرسيوني به دست آمده آن است كه رابطه بين نمرات درس رياضي ( بعنوان متغير وابسته( و نمرات ساير دروس ( به عنوان متغيرهاي مستقل( را مي توان به شكل مدل رياضي زير نشان داد. كه اين مدل معني دار است و نيز وجود هر كدام از ضرايب در مدل معني دار است. ضريب تعيين مدل است يعني درصد از تغييرات يا پراكندگي در نمرات درس رياضي توسط مدل فوق به نمرات اين چهار درس بستگي دارد. بنابراين با معلوم بودن نمرات اين چهار درس براي يك دانش آموز و قرار دادن آنها در مدل فوق مي توان نمره درس رياضي آن دانش آموز را پيش بيني كرد كه خطاي استاندارد اين پيش بيني 2. است. مثال فرض كنيد دانش آموزي در دروس علوم حرفه وفن 86
87 زبان و فارسي به ترتيب نمرات و گرفته باشد. در اينصورت با قرار دادن اين مقادير به جاي متغيرهاي در معادله فوق مقدار برابر خواهد شد با. يعني پيش بيني مي شود كه نمره رياضي اين دانش آموز شود و نيز نمره واقعي رياضي اين دانش آموز به طور متوسط بيشتر يا كمتر از خواهد بود. توجه : در يك مدل چندگانه اگر وجود برخي از متغيرهاي مستقل در مدل معني دار نبود يعني بايد آن متغيرها را از مدل خارج كرده و مجددا مدل ديگري بر متغيرهاي باقي مانده برازش كرده و معني دار بودن متغيرها مجددا آزمون شود. اما در يك مدل رگرسيوني صرفنظر از اينكه وجود ثابت ( ) در مدل معني دار بوده يا معني دار نباشد همواره بايد ثابت معادله يا همان در مدل وجود داشته باشد. مگر آنكه دليل نظري قوي مبني بر عدم وجود آن در مدل وجود داشته باشد. توجه : پس از برازش مدل رگرسيون و با قرار دادن مقادير متغيرهاي مستقل در اين مدل مقاديري براي متغير وابسته بدست مي آيد كه آنها را مقادير پيش بيني شده يا گفته و با نشان مي دهيم. اختالف مقادير پيش بيني شده با مقادير واقعي متغير وابسته را باقيمانده يا مانده يا گوييم و آنها را با نشان مي دهيم يعني كه اگر مدل مدل مناسبي باشد انتظار داريم ها كوچك باشد. توجه )تعيين سهم هر متغير در پراكندگي كل(: همانطوريكه مي دانيم ضريب تعيين بيانگر ميزان از تغييرات يا پراكندگي در متغير وابسته است كه توسط متغيرهاي مستقل تبيين مي شود و در يك رگرسيون چندگانه ضريب تعيين در واقع مجذور ضريب همبستگي چندگانه است. با محاسبه برخي ضرائب همبستگي و مجذور كردن آنها مي توان سهم هر كدام از متغيرهاي پيشگو را در پراكندگي كل تعيين كرد. بدين منظور كافي است در مسير رگرسيون و در پنجره Linear Regression بر روي تب Statistics كليك كرده و در پنجره ظاهر شده coefficients گزينه Part and partial correlations را تيك بزنيم. در خروجي و در جدول سه ستون با نام داده خواهد شد. ستون اول با نام ستون دوم با نام Part و ستون سوم با نام Partial Zero-order correlations 87
88 خواهد بود. ستون Zero-order ضرائب همبستگي مرتبه صفر است. اين ضريب در واقع ضريب همبستگي ساده بين هركدام از متغيرهاي پيشگو با متغير پاسخ است كه در تحليل رگرسيون چندگانه كاربردي ندارد. ستون دوم با نام Partial ضريب همبستگي جزئي بين هر متغير پيشگو با متغير پاسخ است كه ساير متغيرهاي پيشگو به عنوان متغير كنترل در نظر گرفته شده اند. راجع به ضريب همبستگي جزئي و كاربرد آن قبال بطور مفصل بحث شده است. با مجذور كردن اين ضرائب مي توان سهم هر متغير در پراكندگي كل را پس از حذف اثر ساير پيشگوها تعيين كرد. مثال فرض كنيد در يك رگرسيون چندگانه با چهار متغير پيشگوي X,X2,X3,X4 و متغير پاسخ Y ضريب همبستگي جزئي X عدد 0432 به دست آمده باشد. مجذور اين عدد حدودا خواهد بود و اين به آن معني است كه 0 درصد از پراكندگي باقيمانده در متغير پاسخ را كه ساير متغيرهاي پيشگو 0.0 نتوانسته اند تبيين كنند توسط متغير پيشگوي X تبيين مي شود. هرچقدر اين ضريب براي متغيري بزرگتر باشد بيانگر تاثير بيشتر آن متغير در پراكندگي كل است. ستون سوم با نام Part ضريب همبستگي مولفه هركدام از متغيرهاي پيشگو است. ضريب همبستگي مولفه كه آن را ضريب همبستگي نيمه جزئي Correlation( )Semi-Partial نيز مي نامند بيانگر همبستگي منحصر به فرد يك متغير پيشگو با متغير پاسخ است كه از مجذور كردن آن سهم آن متغير در پراكندگي كل متغبر پاسخ به دست مي آيد. پيش فرض هاي رگرسيون ( فرضيه هاي اوليه( در انجام يك تحليل رگرسيوني بعضي فرضيه هاي اوليه وجود دارد كه اين فرضيه ها بايد برقرار باشد و در صورت عدم برقراري اين فرضيه ها اعتبار مدل رگرسيون زير سؤال مي رود اين پيش فرض ها به صورت زير است.. متغير وابسته يا همان متغير پاسخ يك متغير تصادفي پيوسته در سطح اندازه گيري الاقل فاصله اي و توزيع آن نرمال است.. متغيرهاي مستقل يا همان متغيرهاي پيشگو متغيرهايي تصادفي يا غير تصادفي و نا هم بسته اند. باقيمانده هاي مدل ( ها( متغيرهاي تصادفي داراي توزيع نرمال با ميانگين صفر و واريانس ثابت يعني هستند... و نيز اين باقيمانده ها دو به دو نا همبسته اند يعني ) ( 88
89 بررسي پيش فرض هاي رگرسيون. بررسي فرض نرمال بودن: براي بررسي فرض نرمال بودن توزيع متغير پاسخ كافي است نرمال بودن توزيع باقيمانده ها مورد بررسي قرار گيرد چون اگر توزيع باقيمانده ها نرمال باشد توزيع متغير پاسخ نيز نرمال خواهد بود. براي بررسي فرض نرمال بودن توزيع باقيمانده ها هم مي توان هيستوگرام و نمودار احتمال نرمال ( ) باقيمانده هاي استاندارد شده را رسم كرد كه در چنين صورتي فرض نرمال بودن اين متغير به صورت چشمي مورد بررسي قرار مي گيرد. عالوه بر رسم نمودار مي توان از آزمونهاي آماري نيز كمك گرفت. بررسي نموداري فرض نرمال بودن توزیع باقيمانده ها: براي بررسي فرض نرمال بودن توزيع باقيمانده ها هم مي توان هيستوگرام و از هم مي توان از نمودار احتمال نرمال ( ) باقيمانده هاي استاندارد شده استفاده كرد. نمودار احتمال نرمال ( ) نموداري است كه در آن مقادير تابع توزيع تجربي نمونه در مقابل تابع توزيع نرمال در صفحه رسم مي شود اگر توزيع متغير مورد نظر نرمال باشد اين نقاط بر روي نيمساز ربع اول قرار مي گيرند. هر چقدر اين نقاط از نيمساز ربع اول انحراف بيشتري داشته باشد بيانگر عدم نرمال بودن توزيع آن متغير است. براي رسم هستيوگرام و نمودار باقيمانده هاي استاندارد شده در پنجره رگرسيون خطي بر روي گزينه كليك و در پنجره ظاهر شده و در بخش Standardized Residual Plots مي توان تعيين كرد كه اين دو نمودار در خروجي رسم شود اين دو نمودار در مدل مثال قبل رسم شده و در زير آمده است. 89
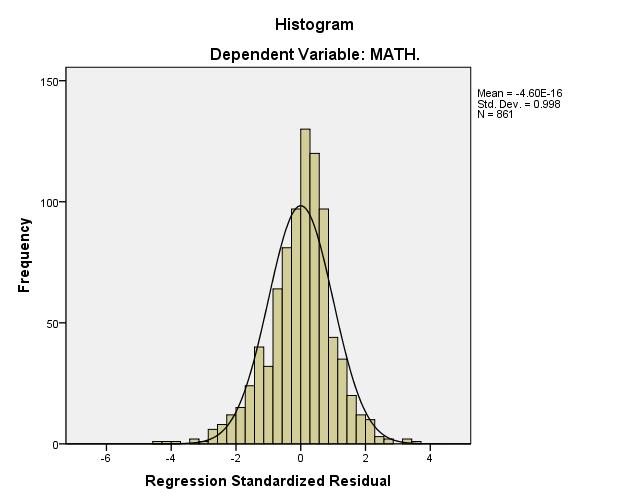

90 90
91 اولين نمودار هيستوگرام و منحني فراواني باقيمانده هاي استاندارد شده است كه چون حجم داده ها خيلي زياد است به نظر مي رسد اين نمودار شبيه به منحني نرمال است. البته كشيدگي آن بيشتر از نرمال به نظر مي رسد و نيز به جهت حجم زياد داده ها نمي تواند به خوبي چولگي داده ها را نشان دهد.در نمودار و با توجه به اينكه حجم داده ها خيلي زياد است مي توان تشخيص داد كه انحراف اين نقاط از نيمساز ربع اول كمي زياد است و بنابراين فرض نرمال بودن توزيع باقيمانده ها به طور چشمي قابل قبول نيست. بررسي فرض نرمال بودن توزیع باقيمانده ها توسط آزمونهاي آماري: عالوه بر بررسي نموداري توزيع باقيمانده ها مي توان فرض نرمال بودن آنها را توسط برخي آزمونهاي آماري مانند آزمون ناپارامتري با نام آزمون نيکویي برازش كولموگروف-اسميرنف و نيز آزمون شاپيرو ویلک انجام داد. آزمون شاپيرو- ويلك قويتر از كولموگروف- اسميرنف است. در هر كدام از اين آزمونها فرضيه مورد بررسي به صورت زير است. { توزيع متغير مورد نظر نرمال است توزيع متغير مورد نظر نرمال نيست براي انجام آزمون نرمال بودن توزيع يك متغير توسط آزمون نيكويي برازش كولموگروف- اسميرنف و نيز آزمون شاپيرو-ويلك از مسير زير استفاده مي كنيم: در اين مثال براي بررسي نرمال بودن توزيع باقيمانده ها و باقيمانده هاي استاندارد شده الزم است ابتدا آنها را به عنوان متغيرهاي جديد در فايل داده ذخيره كرده و سپس نرمال بودن آنها را مورد آزمون قرار مي دهيم. الزم به ذكر است كه براي آزمون نرمال بودن توزيع باقيمانده ها مي توان از باقيمانده هاي استاندارد شده استفاده كرد و در هر صورت نتيجه يكسان است يعني اگر توزيع باقيمانده ها نرمال باشد توزيع باقيمانده هاي استاندارد شده نيز نرمال خواهد بود و بالعكس. براي ذخيره كردن باقيمانده ها و باقيمانده هاي استاندارد شده در فايل داده در پنجره رگرسيون خطي بر روي گزينه كليك كرده و در پنجره ظاهر شده و در قسمت Residuals تعيين مي كنيم كه باقيمانده ها و باقيمانده هاي استاندارد شده ذخيره شود. پس از ذخيره كردن باقيمانده ها و باقيمانده هاي استاندارد شده براي بررسي نرمال بودن آنها به مسير فوق الذكر رفته و در پنجره ظاهر شده 9
92 متغير يا متغيرهائي كه مي خواهيم نرمال بودن توزيع آنها را آزمون كنيم ( در اينجا متغير باقيمانده هاي استاندارد شده( را به Normality plots قسمت مي بريم. سپس بر روي تب Plots كليك كرده و در پنجره ظاهر شده گزينه Dependent List with tests را تيك مي زنيم. پس از اجراي اين فرمان شاخصهاي آماري اين متغير نمدار ساقه و برگ نمودار جعبه اي نموداري با نام نمودار Q-Q Plot و نيز نتيجه آزمون نرماليتي در خروجي داده خواهد شد. نتيجه آزمون نرماليتي در جدولي به صورت زير در خروجي خواهد آمد. Tests of Normality Kolmogorov-Smirnov a Shapiro-Wilk Statistic df Sig. Statistic df Sig. Standardized Residual a. Lilliefors Significance Correction در اين جدول سه ستون اول آن نتيجه آزمون كولموگروف-اسميرنف و سه ستون بعدي آن نتيجه آزمون شاپيرو-ويلك است. در هر كدام از اين دو آزمون ستون آخر با عنوان همان Sig. p-value هاي اين دو آزمون است كه در اين مثال p-value براي هر دو آزمون تا سه رقم اعشار صفر بوده و بنابراين فرض نرمال بودن توزيع باقيمانده هاي استاندارد شده توسط هر دو آزمون رد مي Q-Q plot شود. اين نتيجه از نمودار Q-Q plot كه در خروجي اجراي اين فرمان آمده است نيز به دست مي آيد. نمودار شبيه به نمودار P-P plot است با اين تفاوت كه در اين نمودار صدكهاي به دست آمده در توزيع تجربي نمونه در مقابل صدكهاي توزيع نرمال رسم مي شود. اگر توزيع متغير نرمال باشد بايد نقاط نمونه بر روي نيمساز ربع اول و سوم قرار گيرد. هر چقدر انحراف نقاط از نيمساز بيشتر باشد بيانگر انحراف توزيع آن متغير از توزيع نرمال است. نمودار Q-Q plot در اين مثال به صورت زير است. 92

93 در اين نمودار و با توجه به حجم زياد داده ها مي توان مشاهده كرد كه انحراف نقاط از نيمساز زياد بوده و بر اين اساس فرض نرمال بودن توسط اين نمودار نيز رد مي شود. تبدیالت تواني ( تبدیالت باكس-كاكس( اما اگر توزيع باقيمانده ها نرمال نباشد بايد با انجام يك تبديل مناسب بر روي متغير وابسته توزيع آنرا نرمال كرد. بدين منظور چولگي باقيمانده ها را محاسبه مي كنيم. اگر باقيمانده هاي چوله به راست باشند ( چولگي مثبت ) اكثرا انجام تبديل لگاريتمي باعث نرمال شدن آنها مي شود يعني در چنين حالتي به جاي اينكه از متغير وابسته y در مدل استفاده كنيم از لگاريتم آن يعني Lny در مدل استفاده مي كنيم كه در چنين صورتي مدل رگرسيون به شكل زير تبديل مي شود. 93
94 و اگر باقيمانده ها چوله به چپ باشد )چولگي منفي ) اكثرا تبديل حالتي به جاي استفاده از متغير وابسته y از توان دوم آن يعني باعث نرمال شدن توزيع باقيمانده ها مي شود.يعني در چنين در مدل استفاده مي كنيم كه در چنين صورتي مدل رگرسيون به صورت زير تبديل مي شود. به طور كلي اگر توزیع متغيري مانند y نرمال نبوده و چوله به چپ باشد انجام تبدیل λ توزیع كه λ λ توزیع آنرا نرمال مي كند. و توجه كنيد λ آنرا نرمال مي كند و اگر چولگي به راست باشد تبدیل كه. Lny معادل تبدیل لگاریتمي است یعني 0=λ گاهي اوقات نيز عدم نرمال بودن توزيع باقيمانده ها به جهت وجود داده هاي دور افتاده است. براي شناسايي داده هاي دور افتاده ) كافي است مشاهداتي كه باقيمانده استاندارد شده آنها خارج از فاصله ( -( و به خصوص خارج از فاصله ي ( است را شناسايي كرده و آنها را به عنوان داده دور افتاده از تحليل خارج كنيم. البته هميشه حذف دور افتاده ها جايز نيست و گاهي اوقات چنين داده هايي نبايد حذف شود و در چنين مواردي بايد از مدلهاي غير خطي استفاده كرد. مثال: در مثال قبل همانطوري كه مشاهده شد فرض نرمال بودن توزيع باقيمانده ها رد شد حال با محاسبه چولگي باقيمانده ه يا استاندارد شده و انجام يك تبديل مناسب بر روي متغير وابسته نرمال بودن توزيع باقيمانده ها را مجددا بررسي مي كنيم. با محاسبه چولگي باقيمانده هاي استاندارد شده مشاهده مي شود ميزان چولگي - بوده و بنابراين باقيمانده ها چوله به چپ λ است و لذا در اين مدل به جاي كه از است استفاده مي كنيم. با قرار دادن مقادير مختلف مثبت براي λ و به y روش آزمون و خطا بهترين مقدار براي λ بطوريكه مدل و كليه متغيرها در مدل معني دار بوده و به عالوه توزيع باقيمانده ها نيز λ نرمال باشد مقدار 2.3 براي λ به دست آمد. بنابراين براي اين مدل را برازش كرده و فرض نرمال بودن باقيمانده هاي آنرا آزمون مي كنيم. بدين منظور ابتدا توسط فرمان در مسير Transform Computr variable Compute variable متغير جديدي ايجاد مي كنيم كه اين متغير 2.3 توان متغير مربوط به نمرات درس رياضي دانش آموزان )x4( است. نام اين متغير را Y3.2 مي گذاريم. سپس مجددا رگرسيون چندگانه قبل را انجام مي دهيم با اين تفاوت كه اينبار متغير وابسته متغير Y3.2 ايجاد شده است. نتيجه انجام اين رگرسيون در زير آمده است. 94
95 Model Summary b Model R R Square Adjusted R Square Std. Error of the Estimate.852 a a. Predictors: (Constant), PERSIAN, TECH., SCEIN., FOREI. b. Dependent Variable: Y3.2 ANOVA a Model Sum of Squares df Mean Square F Sig. Regression b Residual Total a. Dependent Variable: Y3.2 b. Predictors: (Constant), PERSIAN, TECH., SCEIN., FOREI. Coefficients a Model Unstandardized Coefficients Standardized Coefficients t Sig. B Std. Error Beta (Constant) SCEIN TECH FOREI PERSIAN a. Dependent Variable: Y3.2 95

96 96
ﻞﻜﺷ V لﺎﺼﺗا ﺎﻳ زﺎﺑ ﺚﻠﺜﻣ لﺎﺼﺗا هﺎﮕﺸﻧاد نﺎﺷﺎﻛ / دﻮﺷ
 1 مبحث بيست و چهارم: اتصال مثلث باز (- اتصال اسكات آرايش هاي خاص ترانسفورماتورهاي سه فاز دانشگاه كاشان / دانشكده مهندسي/ گروه مهندسي برق / درس ماشين هاي الكتريكي / 3 اتصال مثلث باز يا اتصال شكل فرض كنيد
1 مبحث بيست و چهارم: اتصال مثلث باز (- اتصال اسكات آرايش هاي خاص ترانسفورماتورهاي سه فاز دانشگاه كاشان / دانشكده مهندسي/ گروه مهندسي برق / درس ماشين هاي الكتريكي / 3 اتصال مثلث باز يا اتصال شكل فرض كنيد
ﻴﻓ ﯽﺗﺎﻘﻴﻘﺤﺗ و ﯽهﺎﮕﺸﻳﺎﻣزﺁ تاﺰﻴﻬﺠﺗ ﻩﺪﻨﻨﮐ
 دستوركارآزمايش ميز نيرو هدف آزمايش: تعيين برآيند نيروها و بررسي تعادل نيروها در حالت هاي مختلف وسايل آزمايش: ميز مدرج وستون مربوطه, 4 عدد كفه وزنه آلومينيومي بزرگ و قلاب با نخ 35 سانتي, 4 عدد قرقره و پايه
دستوركارآزمايش ميز نيرو هدف آزمايش: تعيين برآيند نيروها و بررسي تعادل نيروها در حالت هاي مختلف وسايل آزمايش: ميز مدرج وستون مربوطه, 4 عدد كفه وزنه آلومينيومي بزرگ و قلاب با نخ 35 سانتي, 4 عدد قرقره و پايه
در اين آزمايش ابتدا راهاندازي موتور القايي روتور سيمپيچي شده سه فاز با مقاومتهاي روتور مختلف صورت گرفته و س سپ مشخصه گشتاور سرعت آن رسم ميشود.
 ك ي آزمايش 7 : راهاندازي و مشخصه خروجي موتور القايي روتور سيمپيچيشده آزمايش 7: راهاندازي و مشخصه خروجي موتور القايي با روتور سيمپيچي شده 1-7 هدف آزمايش در اين آزمايش ابتدا راهاندازي موتور القايي روتور
ك ي آزمايش 7 : راهاندازي و مشخصه خروجي موتور القايي روتور سيمپيچيشده آزمايش 7: راهاندازي و مشخصه خروجي موتور القايي با روتور سيمپيچي شده 1-7 هدف آزمايش در اين آزمايش ابتدا راهاندازي موتور القايي روتور
1 ﺶﻳﺎﻣزآ ﻢﻫا نﻮﻧﺎﻗ ﻲﺳرﺮﺑ
 آزمايش 1 بررسي قانون اهم بررسي تجربي قانون اهم و مطالعه پارامترهاي مو ثر در مقاومت الكتريكي يك سيم فلزي تي وري آزمايش هر و دارند جسم فيزيكي داراي مقاومت الكتريكي است. اجسام فلزي پلاستيك تكه يك بدن انسان
آزمايش 1 بررسي قانون اهم بررسي تجربي قانون اهم و مطالعه پارامترهاي مو ثر در مقاومت الكتريكي يك سيم فلزي تي وري آزمايش هر و دارند جسم فيزيكي داراي مقاومت الكتريكي است. اجسام فلزي پلاستيك تكه يك بدن انسان
برخوردها دو دسته اند : 1) كشسان 2) ناكشسان
 كشسان 2) ناكشسان") آزمايش شماره 8 برخورد (بقاي تكانه) وقتي دو يا چند جسم بدون حضور نيروهاي خارجي طوري به هم نزديك شوند كه بين آنها نوعي برهم كنش رخ دهد مي گوييم برخوردي صورت گرفته است. اغلب در برخوردها خواستار اين هستيم
آزمايش شماره 8 برخورد (بقاي تكانه) وقتي دو يا چند جسم بدون حضور نيروهاي خارجي طوري به هم نزديك شوند كه بين آنها نوعي برهم كنش رخ دهد مي گوييم برخوردي صورت گرفته است. اغلب در برخوردها خواستار اين هستيم
( ) x x. ( k) ( ) ( 1) n n n ( 1) ( 2)( 1) حل سري: حول است. مثال- x اگر. يعني اگر xها از = 1. + x+ x = 1. x = y= C C2 و... و
 x x. ( k) ( ) ( 1) n n n ( 1) ( 2)( 1) حل سري: حول است. مثال- x اگر. يعني اگر xها از = 1. + x+ x = 1. x = y= C C2 و... و") معادلات ديفرانسيل y C ( ) R mi i كه حل سري يعني جواب دقيق ميخواهيم نه به صورت صريح بلكه به صورت سري. اگر فرض كنيم خطي باشد, اين صورت شعاع همگرايي سري فوق, مينيمم اندازه است جواب معادله ديفرانسيل i نقاط
معادلات ديفرانسيل y C ( ) R mi i كه حل سري يعني جواب دقيق ميخواهيم نه به صورت صريح بلكه به صورت سري. اگر فرض كنيم خطي باشد, اين صورت شعاع همگرايي سري فوق, مينيمم اندازه است جواب معادله ديفرانسيل i نقاط
( ) قضايا. ) s تعميم 4) مشتق تعميم 5) انتگرال 7) كانولوشن. f(t) L(tf (t)) F (s) Lf(t ( t)u(t t) ) e F(s) L(f (t)) sf(s) f ( ) f(s) s.
 قضايا. ) s تعميم 4) مشتق تعميم 5) انتگرال 7) كانولوشن. f(t) L(tf (t)) F (s) Lf(t ( t)u(t t) ) e F(s) L(f (t)) sf(s) f ( ) f(s) s.") معادلات ديفرانسيل + f() d تبديل لاپلاس تابع f() را در نظر بگيريد. همچنين فرض كنيد ( R() > عدد مختلط با قسمت حقيقي مثبت) در اين صورت صورت وجود لاپلاس f() نامند و با قضايا ) ضرب در (انتقال درحوزه S) F()
معادلات ديفرانسيل + f() d تبديل لاپلاس تابع f() را در نظر بگيريد. همچنين فرض كنيد ( R() > عدد مختلط با قسمت حقيقي مثبت) در اين صورت صورت وجود لاپلاس f() نامند و با قضايا ) ضرب در (انتقال درحوزه S) F()
+ Δ o. A g B g A B g H. o 3 ( ) ( ) ( ) ; 436. A B g A g B g HA است. H H برابر
 ( ) ( ) ; 436. A B g A g B g HA است. H H برابر") ا نتالپي تشكيل پيوند وا نتالپي تفكيك پيوند: ا نتالپي تشكيل يك پيوندي مانند A B برابر با تغيير ا نتالپي استانداردي است كه در جريان تشكيل ا ن B g حاصل ميشود. ( ), پيوند از گونه هاي (g )A ( ) + ( ) ( ) ;
ا نتالپي تشكيل پيوند وا نتالپي تفكيك پيوند: ا نتالپي تشكيل يك پيوندي مانند A B برابر با تغيير ا نتالپي استانداردي است كه در جريان تشكيل ا ن B g حاصل ميشود. ( ), پيوند از گونه هاي (g )A ( ) + ( ) ( ) ;
10 ﻞﺼﻓ ﺶﺧﺮﭼ : ﺪﻴﻧاﻮﺘﺑ ﺪﻳﺎﺑ ﻞﺼﻓ ﻦﻳا يا ﻪﻌﻟﺎﻄﻣ زا ﺪﻌﺑ
 فصل چرخش بعد از مطالعه اي اين فصل بايد بتوانيد : - مكان زاويه اي سرعت وشتاب زاويه اي را توضيح دهيد. - چرخش با شتاب زاويه اي ثابت را مورد بررسي قرار دهيد. 3- رابطه ميان متغيرهاي خطي و زاويه اي را بشناسيد.
فصل چرخش بعد از مطالعه اي اين فصل بايد بتوانيد : - مكان زاويه اي سرعت وشتاب زاويه اي را توضيح دهيد. - چرخش با شتاب زاويه اي ثابت را مورد بررسي قرار دهيد. 3- رابطه ميان متغيرهاي خطي و زاويه اي را بشناسيد.
هدف:.100 مقاومت: خازن: ترانزيستور: پتانسيومتر:
 آزمايش شماره (10) تقويت كننده اميتر مشترك هدف: هدف از اين آزمايش مونتاژ مدار طراحي شده و اندازهگيري مشخصات اين تقويت كننده جهت مقايسه نتايج اندازهگيري با مقادير مطلوب و در ادامه طراحي يك تقويت كننده اميترمشترك
آزمايش شماره (10) تقويت كننده اميتر مشترك هدف: هدف از اين آزمايش مونتاژ مدار طراحي شده و اندازهگيري مشخصات اين تقويت كننده جهت مقايسه نتايج اندازهگيري با مقادير مطلوب و در ادامه طراحي يك تقويت كننده اميترمشترك
آزمایش 2: تعيين مشخصات دیود پيوندي PN
 آزمایش 2: تعيين مشخصات دیود پيوندي PN هدف در اين آزمايش مشخصات ديود پيوندي PN را بدست آورده و مورد بررسي قرار مي دهيم. وسايل و اجزاي مورد نياز ديودهاي 1N4002 1N4001 1N4148 و يا 1N4004 مقاومتهاي.100KΩ,10KΩ,1KΩ,560Ω,100Ω,10Ω
آزمایش 2: تعيين مشخصات دیود پيوندي PN هدف در اين آزمايش مشخصات ديود پيوندي PN را بدست آورده و مورد بررسي قرار مي دهيم. وسايل و اجزاي مورد نياز ديودهاي 1N4002 1N4001 1N4148 و يا 1N4004 مقاومتهاي.100KΩ,10KΩ,1KΩ,560Ω,100Ω,10Ω
O 2 C + C + O 2-110/52KJ -393/51KJ -283/0KJ CO 2 ( ) ( ) ( )
 ( ) ( )") به كمك قانون هس: هنري هس شيميدان و فيزيكدان سوي يسي - روسي تبار در سال ۱۸۴۰ از راه تجربه دريافت كه گرماي وابسته به يك واكنش شيمياي مستقل از راهي است كه براي انجام ا ن انتخاب مي شود (در دماي ثابت و همچنين
به كمك قانون هس: هنري هس شيميدان و فيزيكدان سوي يسي - روسي تبار در سال ۱۸۴۰ از راه تجربه دريافت كه گرماي وابسته به يك واكنش شيمياي مستقل از راهي است كه براي انجام ا ن انتخاب مي شود (در دماي ثابت و همچنين
e r 4πε o m.j /C 2 =
 فن( محاسبات بوهر نيروي جاذبه الکتروستاتيکي بين هسته و الکترون در اتم هيدروژن از رابطه زير قابل محاسبه F K است: که در ا ن بار الکترون فاصله الکترون از هسته (يا شعاع مدار مجاز) و K ثابتي است که 4πε مقدار
فن( محاسبات بوهر نيروي جاذبه الکتروستاتيکي بين هسته و الکترون در اتم هيدروژن از رابطه زير قابل محاسبه F K است: که در ا ن بار الکترون فاصله الکترون از هسته (يا شعاع مدار مجاز) و K ثابتي است که 4πε مقدار
محاسبه ی برآیند بردارها به روش تحلیلی
 محاسبه ی برآیند بردارها به روش تحلیلی برای محاسبه ی برآیند بردارها به روش تحلیلی باید توانایی تجزیه ی یک بردار در دو راستا ( محور x ها و محور y ها ) را داشته باشیم. به بردارهای تجزیه شده در راستای محور
محاسبه ی برآیند بردارها به روش تحلیلی برای محاسبه ی برآیند بردارها به روش تحلیلی باید توانایی تجزیه ی یک بردار در دو راستا ( محور x ها و محور y ها ) را داشته باشیم. به بردارهای تجزیه شده در راستای محور
حل J 298 كنيد JK mol جواب: مييابد.
 تغيير ا نتروپي در دنياي دور و بر سيستم: هر سيستم داراي يك دنياي دور و بر يا محيط اطراف خود است. براي سادگي دنياي دور و بر يك سيستم را محيط ميناميم. محيط يك سيستم همانند يك منبع بسيار عظيم گرما در نظر گرفته
تغيير ا نتروپي در دنياي دور و بر سيستم: هر سيستم داراي يك دنياي دور و بر يا محيط اطراف خود است. براي سادگي دنياي دور و بر يك سيستم را محيط ميناميم. محيط يك سيستم همانند يك منبع بسيار عظيم گرما در نظر گرفته
روش محاسبه ی توان منابع جریان و منابع ولتاژ
 روش محاسبه ی توان منابع جریان و منابع ولتاژ ابتدا شرح کامل محاسبه ی توان منابع جریان: برای محاسبه ی توان منابع جریان نخست باید ولتاژ این عناصر را بدست آوریم و سپس با استفاده از رابطه ی p = v. i توان این
روش محاسبه ی توان منابع جریان و منابع ولتاژ ابتدا شرح کامل محاسبه ی توان منابع جریان: برای محاسبه ی توان منابع جریان نخست باید ولتاژ این عناصر را بدست آوریم و سپس با استفاده از رابطه ی p = v. i توان این
آزمون مقایسه میانگین های دو جامعه )نمونه های بزرگ(
نمونه های بزرگ(") آزمون مقایسه میانگین های دو جامعه )نمونه های بزرگ( فرض کنید جمعیت یک دارای میانگین و انحراف معیار اندازه µ و انحراف معیار σ باشد و جمعیت 2 دارای میانگین µ2 σ2 باشند نمونه های تصادفی مستقل از این دو جامعه
آزمون مقایسه میانگین های دو جامعه )نمونه های بزرگ( فرض کنید جمعیت یک دارای میانگین و انحراف معیار اندازه µ و انحراف معیار σ باشد و جمعیت 2 دارای میانگین µ2 σ2 باشند نمونه های تصادفی مستقل از این دو جامعه
P = P ex F = A. F = P ex A
 محاسبه كار انبساطي: در ترموديناميك اغلب با كار ناشي از انبساط يا تراكم سيستم روبرو هستيم. براي پي بردن به اين نوع كار به شكل زير خوب توجه كنيد. در اين شكل استوانهاي را كه به يك پيستون بدون اصطكاك مجهز
محاسبه كار انبساطي: در ترموديناميك اغلب با كار ناشي از انبساط يا تراكم سيستم روبرو هستيم. براي پي بردن به اين نوع كار به شكل زير خوب توجه كنيد. در اين شكل استوانهاي را كه به يك پيستون بدون اصطكاك مجهز
بررسي علل تغيير در مصرف انرژي بخش صنعت ايران با استفاده از روش تجزيه
 79 نشريه انرژي ايران / دوره 2 شماره 3 پاييز 388 بررسي علل تغيير در مصرف انرژي بخش صنعت ايران با استفاده از روش تجزيه رضا گودرزي راد تاريخ دريافت مقاله: 89//3 تاريخ پذيرش مقاله: 89/4/5 كلمات كليدي: اثر
79 نشريه انرژي ايران / دوره 2 شماره 3 پاييز 388 بررسي علل تغيير در مصرف انرژي بخش صنعت ايران با استفاده از روش تجزيه رضا گودرزي راد تاريخ دريافت مقاله: 89//3 تاريخ پذيرش مقاله: 89/4/5 كلمات كليدي: اثر
را بدست آوريد. دوران
 تجه: همانطر كه در كلاس بارها تا كيد شد تمرينه يا بيشتر جنبه آمزشي داشت براي يادگيري بيشتر مطالب درسي بده است مشابه اين سه تمرين كه در اينجا حل آنها آمده است در امتحان داده نخاهد شد. m b الف ماتريس تبديل
تجه: همانطر كه در كلاس بارها تا كيد شد تمرينه يا بيشتر جنبه آمزشي داشت براي يادگيري بيشتر مطالب درسي بده است مشابه اين سه تمرين كه در اينجا حل آنها آمده است در امتحان داده نخاهد شد. m b الف ماتريس تبديل
آزمایش 1 :آشنایی با نحوهی کار اسیلوسکوپ
 آزمایش 1 :آشنایی با نحوهی کار اسیلوسکوپ هدف در اين آزمايش با نحوه كار و بخشهاي مختلف اسيلوسكوپ آشنا مي شويم. ابزار مورد نياز منبع تغذيه اسيلوسكوپ Function Generator شرح آزمايش 1-1 اندازه گيري DC با اسيلوسكوپ
آزمایش 1 :آشنایی با نحوهی کار اسیلوسکوپ هدف در اين آزمايش با نحوه كار و بخشهاي مختلف اسيلوسكوپ آشنا مي شويم. ابزار مورد نياز منبع تغذيه اسيلوسكوپ Function Generator شرح آزمايش 1-1 اندازه گيري DC با اسيلوسكوپ
سبد(سرمايهگذار) مربوطه گزارش ميكند در حاليكه موظف است بازدهي سبدگردان را جهت اطلاع عموم در
 مربوطه گزارش ميكند در حاليكه موظف است بازدهي سبدگردان را جهت اطلاع عموم در") بسمه تعالي در شركت هاي سبدگردان بر اساس پيوست دستورالعمل تاسيس و فعاليت شركت هاي سبدگردان مصوب هيي ت مديره سازمان بورس بانجام مي رسد. در ادامه به اراي ه اين پيوست مي پردازيم: چگونگي محاسبه ي بازدهي سبد
بسمه تعالي در شركت هاي سبدگردان بر اساس پيوست دستورالعمل تاسيس و فعاليت شركت هاي سبدگردان مصوب هيي ت مديره سازمان بورس بانجام مي رسد. در ادامه به اراي ه اين پيوست مي پردازيم: چگونگي محاسبه ي بازدهي سبد
1) { } 6) {, } {{, }} 2) {{ }} 7 ) { } 3) { } { } 8) { } 4) {{, }} 9) { } { }
 { } 6) {, } {{, }} 2) {{ }} 7 ) { } 3) { } { } 8) { } 4) {{, }} 9) { } { }") هرگاه دسته اي از اشیاء حروف و اعداد و... که کاملا"مشخص هستند با هم در نظر گرفته شوند یک مجموعه را به وجود می آورند. عناصر تشکیل دهنده ي یک مجموعه باید دو شرط اساسی را داشته باشند. نام گذاري مجموعه : الف
هرگاه دسته اي از اشیاء حروف و اعداد و... که کاملا"مشخص هستند با هم در نظر گرفته شوند یک مجموعه را به وجود می آورند. عناصر تشکیل دهنده ي یک مجموعه باید دو شرط اساسی را داشته باشند. نام گذاري مجموعه : الف
در اين ا زمايش ابتدا راهاندازي موتور القايي رتور سيمپيچي شده سه فاز با مقاومت مختلف بررسي و س سپ مشخصه گشتاور سرعت ا ن رسم ميشود.
 ا زمايش 4: راهاندازي و مشخصه خروجي موتور القايي با رتور سيمپيچي شده 1-4 هدف ا زمايش در اين ا زمايش ابتدا راهاندازي موتور القايي رتور سيمپيچي شده سه فاز با مقاومت مختلف بررسي و س سپ مشخصه گشتاور سرعت ا
ا زمايش 4: راهاندازي و مشخصه خروجي موتور القايي با رتور سيمپيچي شده 1-4 هدف ا زمايش در اين ا زمايش ابتدا راهاندازي موتور القايي رتور سيمپيچي شده سه فاز با مقاومت مختلف بررسي و س سپ مشخصه گشتاور سرعت ا
هر عملگرجبر رابطه ای روی يک يا دو رابطه به عنوان ورودی عمل کرده و يک رابطه جديد را به عنوان نتيجه توليد می کنند.
 8-1 جبررابطه ای يک زبان پرس و جو است که عمليات روی پايگاه داده را توسط نمادهايی به صورت فرمولی بيان می کند. election Projection Cartesian Product et Union et Difference Cartesian Product et Intersection
8-1 جبررابطه ای يک زبان پرس و جو است که عمليات روی پايگاه داده را توسط نمادهايی به صورت فرمولی بيان می کند. election Projection Cartesian Product et Union et Difference Cartesian Product et Intersection
است). ازتركيب دو رابطه (1) و (2) داريم: I = a = M R. 2 a. 2 mg
. ازتركيب دو رابطه (1) و (2) داريم: I = a = M R. 2 a. 2 mg") دستوركارآزمايش ماشين آتوود قانون اول نيوتن (قانون لختي يا اصل ماند): جسمي كه تحت تا ثيرنيروي خارجي واقع نباشد حالت سكون يا حركت راست خط يكنواخت خود را حفظ مي كند. قانون دوم نيوتن (اصل اساسي ديناميك): هرگاه
دستوركارآزمايش ماشين آتوود قانون اول نيوتن (قانون لختي يا اصل ماند): جسمي كه تحت تا ثيرنيروي خارجي واقع نباشد حالت سكون يا حركت راست خط يكنواخت خود را حفظ مي كند. قانون دوم نيوتن (اصل اساسي ديناميك): هرگاه
آزمايش (٤) موضوع آزمايش: تداخل به وسيلهي دو شكاف يانگ و دو منشور فرنل
 موضوع آزمايش: تداخل به وسيلهي دو شكاف يانگ و دو منشور فرنل") آزمايش (٤) موضوع آزمايش: تداخل به وسيلهي دو شكاف يانگ و دو منشور فرنل وسايل مورد نياز: طيف سنج دو شكاف يانگ لامپ سديم و منبع تغذيه ليزر هليوم نئون دو منشور فرنل دو عدد عدسي خط كش چوبي كوليس ريل اپتيكي
آزمايش (٤) موضوع آزمايش: تداخل به وسيلهي دو شكاف يانگ و دو منشور فرنل وسايل مورد نياز: طيف سنج دو شكاف يانگ لامپ سديم و منبع تغذيه ليزر هليوم نئون دو منشور فرنل دو عدد عدسي خط كش چوبي كوليس ريل اپتيكي
(,, ) = mq np داريم: 2 2 »گام : دوم« »گام : چهارم«
 = mq np داريم: 2 2 »گام : دوم« »گام : چهارم«") 3 8 بردارها خارجي ضرب مفروضاند. (,, ) 3 و (,, 3 ) بردار دو تعريف: و ميدهيم نمايش نماد با را آن كه است برداري در خارجي ضرب ( 3 3, 3 3, ) m n mq np p q از: است عبارت ماتريس دترمينان در اينكه به توجه با اما
3 8 بردارها خارجي ضرب مفروضاند. (,, ) 3 و (,, 3 ) بردار دو تعريف: و ميدهيم نمايش نماد با را آن كه است برداري در خارجي ضرب ( 3 3, 3 3, ) m n mq np p q از: است عبارت ماتريس دترمينان در اينكه به توجه با اما
فصل اول آشنايي با Excel
 فصل اول آشنايي با Excel 1 هدفهاي رفتاري پس از پايان اين فصل هنرجو بايد در Excel بتواند : 1- قسمتهاي مختلف محيط كار Excel را بشناسد. 2- كاربرد شكلهاي مختلف حالت ماوس را بشناسد. 3- با كاربرد روبانهاي مختلف
فصل اول آشنايي با Excel 1 هدفهاي رفتاري پس از پايان اين فصل هنرجو بايد در Excel بتواند : 1- قسمتهاي مختلف محيط كار Excel را بشناسد. 2- كاربرد شكلهاي مختلف حالت ماوس را بشناسد. 3- با كاربرد روبانهاي مختلف
a a VQ It ميانگين τ max =τ y= τ= = =. y A bh مثال) مقدار τ max b( 2b) 3 (b 0/ 06b)( 1/ 8b) 12 12
 مقدار τ max b( 2b) 3 (b 0/ 06b)( 1/ 8b) 12 12") مقاومت مصالح بارگذاري عرضي: بارگذاري عرضي در تيرها باعث ايجاد تنش برشي ميشود كه مقدار آن از رابطه زير قابل محاسبه است: كه در اين رابطه: - : x h q( x) τ mx τ ( τ ) = Q I برش در مقطع مورد نظر در طول تير
مقاومت مصالح بارگذاري عرضي: بارگذاري عرضي در تيرها باعث ايجاد تنش برشي ميشود كه مقدار آن از رابطه زير قابل محاسبه است: كه در اين رابطه: - : x h q( x) τ mx τ ( τ ) = Q I برش در مقطع مورد نظر در طول تير
هدف: LED ديودهاي: 4001 LED مقاومت: 1, اسيلوسكوپ:
 آزمايش شماره (1) آشنايي با انواع ديود ها و منحني ولت -آمپر LED هدف: هدف از اين آزمايش آشنايي با پايه هاي ديودهاي معمولي مستقيم و معكوس مي باشد. و زنر همراه با رسم منحني مشخصه ولت- آمپر در دو گرايش وسايل
آزمايش شماره (1) آشنايي با انواع ديود ها و منحني ولت -آمپر LED هدف: هدف از اين آزمايش آشنايي با پايه هاي ديودهاي معمولي مستقيم و معكوس مي باشد. و زنر همراه با رسم منحني مشخصه ولت- آمپر در دو گرايش وسايل
V o. V i. 1 f Z c. ( ) sin ورودي را. i im i = 1. LCω. s s s
 sin ورودي را. i im i = 1. LCω. s s s") گزارش کار ا زمايشگاه اندازهگيري و مدار ا زمايش شمارهي ۵ مدار C سري خروجي خازن ۱۳ ا بانماه ۱۳۸۶ ي م به نام خدا تي وري ا زمايش به هر مداري که در ا ن ترکيب ي از مقاومت خازن و القاگر به کار رفتهشده باشد مدار
گزارش کار ا زمايشگاه اندازهگيري و مدار ا زمايش شمارهي ۵ مدار C سري خروجي خازن ۱۳ ا بانماه ۱۳۸۶ ي م به نام خدا تي وري ا زمايش به هر مداري که در ا ن ترکيب ي از مقاومت خازن و القاگر به کار رفتهشده باشد مدار
خطا انواع. (Overflow/underflow) (Negligible addition)
 (Negligible addition)") محاسبات عدديپي پيشرفته فصل اوليه مفاهيم خطا انواع با افزايش دقت از جمع تعداد محدود ارقام حاصل ميشود. (Truncation برش: error) خطاي (Precision) اين خطا كم مي شود. در نمايش يا ذخيره نمودن مقادير عددي با تعداد
محاسبات عدديپي پيشرفته فصل اوليه مفاهيم خطا انواع با افزايش دقت از جمع تعداد محدود ارقام حاصل ميشود. (Truncation برش: error) خطاي (Precision) اين خطا كم مي شود. در نمايش يا ذخيره نمودن مقادير عددي با تعداد
تصاویر استریوگرافی.
 هب انم خدا تصاویر استریوگرافی تصویر استریوگرافی یک روش ترسیمی است که به وسیله آن ارتباط زاویه ای بین جهات و صفحات بلوری یک کریستال را در یک فضای دو بعدی )صفحه کاغذ( تعیین میکنند. کاربردها بررسی ناهمسانگردی
هب انم خدا تصاویر استریوگرافی تصویر استریوگرافی یک روش ترسیمی است که به وسیله آن ارتباط زاویه ای بین جهات و صفحات بلوری یک کریستال را در یک فضای دو بعدی )صفحه کاغذ( تعیین میکنند. کاربردها بررسی ناهمسانگردی
مقدمه -1-4 تحليلولتاژگرهمدارهاييبامنابعجريان 4-4- تحليلجريانمشبامنابعولتاژنابسته
 مقدمه -1-4 تحليلولتاژگرهمدارهاييبامنابعجريان -2-4 بامنابعجريانوولتاژ تحليلولتاژگرهمدارهايي 3-4- تحليلولتاژگرهبامنابعوابسته 4-4- تحليلجريانمشبامنابعولتاژنابسته 5-4- ژاتلو و 6-4 -تحليلجريانمشبامنابعجريان
مقدمه -1-4 تحليلولتاژگرهمدارهاييبامنابعجريان -2-4 بامنابعجريانوولتاژ تحليلولتاژگرهمدارهايي 3-4- تحليلولتاژگرهبامنابعوابسته 4-4- تحليلجريانمشبامنابعولتاژنابسته 5-4- ژاتلو و 6-4 -تحليلجريانمشبامنابعجريان
یﺭﺎﺘﻓﺭ یﺭﺎﺘﻓﺭ یﺎﻫ یﺎﻫ ﻑﺪﻫ ﻑﺪﻫ
 دهم فصل اندازه گذارى ساعات آموزش نظری عملی جمع ٤ ٣ ١ فصل دهم كند. های رفتاری هدف پس از پايان اين فصل از هنرجو انتظار می رود: 1 لزوم اندازه گذاری را تعريف كند. 2 علايم اندازه گذاری را طبق استاندارد شناسايی
دهم فصل اندازه گذارى ساعات آموزش نظری عملی جمع ٤ ٣ ١ فصل دهم كند. های رفتاری هدف پس از پايان اين فصل از هنرجو انتظار می رود: 1 لزوم اندازه گذاری را تعريف كند. 2 علايم اندازه گذاری را طبق استاندارد شناسايی
آزمایش 8: تقویت کننده عملیاتی 2
 آزمایش 8: تقویت کننده عملیاتی 2 1-8 -مقدمه 1 تقویت کننده عملیاتی (OpAmp) داراي دو یا چند طبقه تقویت کننده تفاضلی است که خروجی- هاي هر طبقه به وروديهاي طبقه دیگر متصل شده است. در انتهاي این تقویت کننده
آزمایش 8: تقویت کننده عملیاتی 2 1-8 -مقدمه 1 تقویت کننده عملیاتی (OpAmp) داراي دو یا چند طبقه تقویت کننده تفاضلی است که خروجی- هاي هر طبقه به وروديهاي طبقه دیگر متصل شده است. در انتهاي این تقویت کننده
فصل چهارم آشنايي با اتوكد 2012 فصل چهارم
 55 فصل چهارم آشنايي با اتوكد 2012 56 هدفهاي رفتاري پس از پايان اين فصل هنرجو بايد در AutoCAD بتواند : 1- قسمت هاي مختلف محيط كار AutoCAD را بشناسد. 2- با كاربرد روبانهاي مختلف آشنايي كلي داشته باشد. 3-
55 فصل چهارم آشنايي با اتوكد 2012 56 هدفهاي رفتاري پس از پايان اين فصل هنرجو بايد در AutoCAD بتواند : 1- قسمت هاي مختلف محيط كار AutoCAD را بشناسد. 2- با كاربرد روبانهاي مختلف آشنايي كلي داشته باشد. 3-
همبستگی و رگرسیون در این مبحث هدف بررسی وجود یک رابطه بین دو یا چند متغیر می باشد لذا هدف اصلی این است که آیا بین
 همبستگی و رگرسیون در این مبحث هدف بررسی وجود یک رابطه بین دو یا چند متغیر می باشد لذا هدف اصلی این است که آیا بین دو صفت متغیر x و y رابطه و همبستگی وجود دارد یا خیر و آیا می توان یک مدل ریاضی و یک رابطه
همبستگی و رگرسیون در این مبحث هدف بررسی وجود یک رابطه بین دو یا چند متغیر می باشد لذا هدف اصلی این است که آیا بین دو صفت متغیر x و y رابطه و همبستگی وجود دارد یا خیر و آیا می توان یک مدل ریاضی و یک رابطه
Distributed Snapshot DISTRIBUTED SNAPSHOT سپس. P i. Advanced Operating Systems Sharif University of Technology. - Distributed Snapshot ادامه
 Distributed Snapshot يك روش براي حل GPE اين بود كه پردازهي مبصر P 0 از ديگر پردازهها درخواست كند تا حالت محلي خود را اعلام كنند و سپس آنها را باهم ادغام كند. اين روش را Snapshot گوييم. ولي حالت سراسري
Distributed Snapshot يك روش براي حل GPE اين بود كه پردازهي مبصر P 0 از ديگر پردازهها درخواست كند تا حالت محلي خود را اعلام كنند و سپس آنها را باهم ادغام كند. اين روش را Snapshot گوييم. ولي حالت سراسري
1- مقدمه است.
 آموزش بدون نظارت شبكه عصبي RBF به وسيله الگوريتم ژنتيك محمدصادق محمدي دانشكده فني دانشگاه گيلان Email: m.s.mohammadi@gmail.com چكيده - در اين مقاله روشي كار آمد براي آموزش شبكه هاي عصبي RBF به كمك الگوريتم
آموزش بدون نظارت شبكه عصبي RBF به وسيله الگوريتم ژنتيك محمدصادق محمدي دانشكده فني دانشگاه گيلان Email: m.s.mohammadi@gmail.com چكيده - در اين مقاله روشي كار آمد براي آموزش شبكه هاي عصبي RBF به كمك الگوريتم
فصل چهارم: جبر رابطه اي
 فصل چهارم: جبر ه اي عملوند ها اعداد هستند. که با آن بخوبي آشنا هستيم جبر هاي در جبر رياضي حاصل يک عدد ديگر مي و عدد انجام مي شود دو عملگري )مثل +( روي مثال جبري است که که بحث اين فصل از کتاب است جبر ه
فصل چهارم: جبر ه اي عملوند ها اعداد هستند. که با آن بخوبي آشنا هستيم جبر هاي در جبر رياضي حاصل يک عدد ديگر مي و عدد انجام مي شود دو عملگري )مثل +( روي مثال جبري است که که بحث اين فصل از کتاب است جبر ه
چكيده SPT دارد.
 ارايه يك روش چيدمان خلاقانه جديد براي زمانبندي دسترسي به شبكه جهت كاهش انجام درخواستها سهراب خانمحمدي سولماز عبدالهي زاد استاد گروه مهندسي كنترل دانشگاه تبريز تبريز ايران Khamohammadi.sohrab@tabrizu.ac.ir
ارايه يك روش چيدمان خلاقانه جديد براي زمانبندي دسترسي به شبكه جهت كاهش انجام درخواستها سهراب خانمحمدي سولماز عبدالهي زاد استاد گروه مهندسي كنترل دانشگاه تبريز تبريز ايران Khamohammadi.sohrab@tabrizu.ac.ir
ˆÃd. ¼TvÃQ (1) (2) داشت: ( )
 (2) داشت: ( )") تغيير ا نتالپي : ΔH بيشتر واكنشها در شيمي در فشار ثابت انجام ميگيرند. سوختن كبريت در هواي ا زاد و همچنين واكنش خنثي شدن سود با سولفوريك اسيد در يك بشر نمونه اي از واكنشهايي هستند كه در فشار ثابت انجام
تغيير ا نتالپي : ΔH بيشتر واكنشها در شيمي در فشار ثابت انجام ميگيرند. سوختن كبريت در هواي ا زاد و همچنين واكنش خنثي شدن سود با سولفوريك اسيد در يك بشر نمونه اي از واكنشهايي هستند كه در فشار ثابت انجام
R = V / i ( Ω.m كربن **
 مقاومت مقاومت ويژه و رسانندگي اگر سرهاي هر يك از دو ميله مسي و چوبي را كه از نظر هندسي مشابهند به اختلاف پتانسيل يكساني وصل كنيم جريانهاي حاصل در ا نها بسيار متفاوت خواهد بود. مشخصهاي از رسانا كه در اينجا
مقاومت مقاومت ويژه و رسانندگي اگر سرهاي هر يك از دو ميله مسي و چوبي را كه از نظر هندسي مشابهند به اختلاف پتانسيل يكساني وصل كنيم جريانهاي حاصل در ا نها بسيار متفاوت خواهد بود. مشخصهاي از رسانا كه در اينجا
نيمتوان پرتو مجموع مجموع) منحني
 منحني") شبيه سازي مقايسه و انتخاب روش بهينه پيادهسازي ردگيري مونوپالس در يك رادار آرايه فازي عباس نيك اختر حسن بولوردي صنايع الكترونيك شيراز Abbas.nikakhtar@Gmail.com صنايع الكترونيك شيراز hasan_bolvardi@yahoo.com
شبيه سازي مقايسه و انتخاب روش بهينه پيادهسازي ردگيري مونوپالس در يك رادار آرايه فازي عباس نيك اختر حسن بولوردي صنايع الكترونيك شيراز Abbas.nikakhtar@Gmail.com صنايع الكترونيك شيراز hasan_bolvardi@yahoo.com
1. مقدمه بگيرند اما يك طرح دو بعدي براي عايق اصلي ترانسفورماتور كافي ميباشد. با ساده سازي شكل عايق اصلي بين سيم پيچ HV و سيم پيچ LV به
 No. F-16-TRN-1277 عيب يابي عايق كاغذ روغن ترانسفورماتور قدرت به روش FDS محمد مرتاضي احمد مرادي دانشگاه آزاد اسلامي واحد تهران جنوب تهران ايران چكيده سنجش حوزه ي فركانس سيستم هاي عايقي كاغذ روغن روش تشخيص
No. F-16-TRN-1277 عيب يابي عايق كاغذ روغن ترانسفورماتور قدرت به روش FDS محمد مرتاضي احمد مرادي دانشگاه آزاد اسلامي واحد تهران جنوب تهران ايران چكيده سنجش حوزه ي فركانس سيستم هاي عايقي كاغذ روغن روش تشخيص
كار شماره توانايي عنوان آموزش
 پنجم بخش منطقي گيتهاي و ديجيتال : كلي هدف ديجيتال در پايه مدارهاي عملي و نظري تحليل واحد كار شماره توانايي توانايي عنوان آموزش زمان نظري عملي جمع 22 2 آنها كاربرد و ديجيتال سيستمهاي بررسي توانايي 2 U8
پنجم بخش منطقي گيتهاي و ديجيتال : كلي هدف ديجيتال در پايه مدارهاي عملي و نظري تحليل واحد كار شماره توانايي توانايي عنوان آموزش زمان نظري عملي جمع 22 2 آنها كاربرد و ديجيتال سيستمهاي بررسي توانايي 2 U8
اراي ه روشي نوين براي حذف مولفه DC ميراشونده در رلههاي ديجيتال
 o. F-3-AAA- اراي ه روشي نوين براي حذف مولفه DC ميراشونده در رلههاي ديجيتال جابر پولادي دانشكده فني و مهندسي دانشگاه ا زاد اسلامي واحد علوم و تحقيقات تهران تهران ايران مجتبي خدرزاده مهدي حيدرياقدم دانشكده
o. F-3-AAA- اراي ه روشي نوين براي حذف مولفه DC ميراشونده در رلههاي ديجيتال جابر پولادي دانشكده فني و مهندسي دانشگاه ا زاد اسلامي واحد علوم و تحقيقات تهران تهران ايران مجتبي خدرزاده مهدي حيدرياقدم دانشكده
جلسه 3 ابتدا نکته اي در مورد عمل توابع بر روي ماتریس ها گفته می شود و در ادامه ي این جلسه اصول مکانیک کوانتمی بیان. d 1. i=0. i=0. λ 2 i v i v i.
 محاسبات کوانتمی (671) ترم بهار 1390-1391 مدرس: سلمان ابوالفتح بیگی نویسنده: محمد جواد داوري جلسه 3 می شود. ابتدا نکته اي در مورد عمل توابع بر روي ماتریس ها گفته می شود و در ادامه ي این جلسه اصول مکانیک
محاسبات کوانتمی (671) ترم بهار 1390-1391 مدرس: سلمان ابوالفتح بیگی نویسنده: محمد جواد داوري جلسه 3 می شود. ابتدا نکته اي در مورد عمل توابع بر روي ماتریس ها گفته می شود و در ادامه ي این جلسه اصول مکانیک
چكيده. Keywords: Nash Equilibrium, Game Theory, Cournot Model, Supply Function Model, Social Welfare. 1. مقدمه
 اثرات تراكم انتقال بر نقطه تعادل بازار برق در مدل هاي كورنات و Supply Function منصوره پيدايش * اشكان رحيمي كيان* سيد محمدحسين زندهدل * مصطفي صحراي ي اردكاني* *دانشكده مهندسي برق و كامپيوتر- دانشگاه تهران
اثرات تراكم انتقال بر نقطه تعادل بازار برق در مدل هاي كورنات و Supply Function منصوره پيدايش * اشكان رحيمي كيان* سيد محمدحسين زندهدل * مصطفي صحراي ي اردكاني* *دانشكده مهندسي برق و كامپيوتر- دانشگاه تهران
شاخصهای پراکندگی دامنهی تغییرات:
 شاخصهای پراکندگی شاخصهای پراکندگی بیانگر میزان پراکندگی دادههای آماری میباشند. مهمترین شاخصهای پراکندگی عبارتند از: دامنهی تغییرات واریانس انحراف معیار و ضریب تغییرات. دامنهی تغییرات: اختالف بزرگترین و
شاخصهای پراکندگی شاخصهای پراکندگی بیانگر میزان پراکندگی دادههای آماری میباشند. مهمترین شاخصهای پراکندگی عبارتند از: دامنهی تغییرات واریانس انحراف معیار و ضریب تغییرات. دامنهی تغییرات: اختالف بزرگترین و
* خلاصه
 دانشجوي- ششمين كنگره ملي مهندسي عمران 6 و 7 ارديبهشت 39 دانشگاه سمنان سمنان ايران بررسي و مقايسه همگرايي پايداري و دقت در روشهاي گام به گام انتگرالگيري مستقيم زماني 3 سبحان رستمي * علي معينالديني حامد
دانشجوي- ششمين كنگره ملي مهندسي عمران 6 و 7 ارديبهشت 39 دانشگاه سمنان سمنان ايران بررسي و مقايسه همگرايي پايداري و دقت در روشهاي گام به گام انتگرالگيري مستقيم زماني 3 سبحان رستمي * علي معينالديني حامد
ﺪ ﻮﻴﭘ ﻪﻳﻭﺍﺯ ﺯﺍ ﻪﻛ ﺖﺳﺍ ﻂﺧ ﻭﺩ ﻊﻃﺎﻘﺗ ﺯﺍ ﻞﺻﺎﺣ ﻲﻠﺧﺍﺩ ﻪﻳﻭﺍﺯ ﺯﺍ ﺕﺭﺎﺒﻋ ﺪﻧﻮﻴﭘ ﻪﻳﻭﺍﺯ ﻪﻛ ﺪﻫﺩ ﻲﻣ ﻥﺎﺸﻧ ﺮﻳﺯ ﻞﻜﺷ ﻥﺎﺳﻮﻧ ﻝﺎﺣ ﺭﺩ ﹰﺎﻤﺋﺍﺩ ﺎﻬﻤﺗﺍ ﻥﻮﭼ
 طول پيوند Bond lengths همواره در مولكولها اتمهاي متشكله داراي حركت نوساني نسبت به يكديگر ميباشند اگرچه در اثر نوسان اتمها فاصله پيوند ا نها هميشه متغير است با وجود اين در همه پيوندها فاصله متوسطي بين هسته
طول پيوند Bond lengths همواره در مولكولها اتمهاي متشكله داراي حركت نوساني نسبت به يكديگر ميباشند اگرچه در اثر نوسان اتمها فاصله پيوند ا نها هميشه متغير است با وجود اين در همه پيوندها فاصله متوسطي بين هسته
پایگاه داده جلسه 8 محمد علی فرجیان مدرس :محمد علی فرجیان 1
 پایگاه داده جلسه 8 محمد علی فرجیان مدرس :محمد علی فرجیان 1 2/23/2015 فهرست تعاریف مدل رابطهاي انواع کلید جامعیت جبر رابطهاي تعاريف دامنه )Domain( مجموعه تمام مقادیر ممکن براي صفت )Attribute( است. تعاريف
پایگاه داده جلسه 8 محمد علی فرجیان مدرس :محمد علی فرجیان 1 2/23/2015 فهرست تعاریف مدل رابطهاي انواع کلید جامعیت جبر رابطهاي تعاريف دامنه )Domain( مجموعه تمام مقادیر ممکن براي صفت )Attribute( است. تعاريف
هلول و هتسوپ لدب م ١ لکش
 دوفازي با كيفيت صورت مخلوط به اواپراتور به 1- در اواپراتور كولر يك اتومبيل مبرد R 134a با دبي 0.08kg/s جريان دارد. ورودي مبرد مي شود و محيط بيرون در دماي 25 o C وارد از روي اواپراتور از بخار اشباع است.
دوفازي با كيفيت صورت مخلوط به اواپراتور به 1- در اواپراتور كولر يك اتومبيل مبرد R 134a با دبي 0.08kg/s جريان دارد. ورودي مبرد مي شود و محيط بيرون در دماي 25 o C وارد از روي اواپراتور از بخار اشباع است.
متلب سایت MatlabSite.com
 11-F-REN-1712 بررسي اثر مبدلهاي ماتريسي در كاهش اثر نوسانات باد در توربينهاي بادي مغناطيس داي م چكيده علي رضا ناطقي دانشكده برق و كامپيوتر - دانشگاه شهيد بهشتي حسين كاظمي كارگر دانشكده برق و كامپيوتر -
11-F-REN-1712 بررسي اثر مبدلهاي ماتريسي در كاهش اثر نوسانات باد در توربينهاي بادي مغناطيس داي م چكيده علي رضا ناطقي دانشكده برق و كامپيوتر - دانشگاه شهيد بهشتي حسين كاظمي كارگر دانشكده برق و كامپيوتر -
تي وري آزمايش ششم هدف: بررسي ترانزيستور.UJT
 ب- پ- آزمايشگاه الكترونيك - درس دكتر سبزپوشان تي وري آزمايش ششم هدف: بررسي ترانزيستور.UJT *لطفا قبل از آمدن به آزمايشگاه با مراجعه به كتابهاي درسي تي وري ترانزيستورهاي UJT را مطالعه فرماي يد. Uni )يكي
ب- پ- آزمايشگاه الكترونيك - درس دكتر سبزپوشان تي وري آزمايش ششم هدف: بررسي ترانزيستور.UJT *لطفا قبل از آمدن به آزمايشگاه با مراجعه به كتابهاي درسي تي وري ترانزيستورهاي UJT را مطالعه فرماي يد. Uni )يكي
رياضي 1 و 2. ( + ) xz ( F) خواص F F. u( x,y,z) u = f = + + F = g g. Fx,y,z x y
 xz ( F) خواص F F. u( x,y,z) u = f = + + F = g g. Fx,y,z x y") رياضي و رياضي و F,F,F F= F ˆ ˆ ˆ i+ Fj+ Fk)F ديورژانس توابع برداري ديورژانس ميدان برداري كه توابع اسكالر و حقيقي هستند) به صورت زير تعريف ميشود: F F F div ( F) = + + F= f در اين صورت ديورژانس گراديان,F)
رياضي و رياضي و F,F,F F= F ˆ ˆ ˆ i+ Fj+ Fk)F ديورژانس توابع برداري ديورژانس ميدان برداري كه توابع اسكالر و حقيقي هستند) به صورت زير تعريف ميشود: F F F div ( F) = + + F= f در اين صورت ديورژانس گراديان,F)
مسائل. 2 = (20)2 (1.96) 2 (5) 2 = 61.5 بنابراین اندازه ی نمونه الزم باید حداقل 62=n باشد.
2 (1.96) 2 (5) 2 = 61.5 بنابراین اندازه ی نمونه الزم باید حداقل 62=n باشد.") ) مسائل مدیریت کارخانه پوشاک تصمیم دارد مطالعه ای به منظور تعیین میانگین پیشرفت کارگران کارخانه انجام دهد. اگر او در این مطالعه دقت برآورد را 5 نمره در نظر بگیرد و فرض کند مقدار انحراف معیار پیشرفت کاری
) مسائل مدیریت کارخانه پوشاک تصمیم دارد مطالعه ای به منظور تعیین میانگین پیشرفت کارگران کارخانه انجام دهد. اگر او در این مطالعه دقت برآورد را 5 نمره در نظر بگیرد و فرض کند مقدار انحراف معیار پیشرفت کاری
مقاومت مصالح 2 فصل 9: خيز تيرها. 9. Deflection of Beams
 مقاومت مصالح فصل 9: خيز تيرها 9. Deflection of eams دکتر مح مدرضا نيرومند دااگشنه ايپم نور اصفهان eer Johnston DeWolf ( ) رابطه بين گشتاور خمشی و انحنا: تير طره ای تحت بار متمرکز در انتهای آزاد: P انحنا
مقاومت مصالح فصل 9: خيز تيرها 9. Deflection of eams دکتر مح مدرضا نيرومند دااگشنه ايپم نور اصفهان eer Johnston DeWolf ( ) رابطه بين گشتاور خمشی و انحنا: تير طره ای تحت بار متمرکز در انتهای آزاد: P انحنا
تخمین با معیار مربع خطا: حالت صفر: X: مکان هواپیما بدون مشاهده X را تخمین بزنیم. بهترین تخمین مقداری است که متوسط مربع خطا مینیمم باشد:
 تخمین با معیار مربع خطا: هدف: با مشاهده X Y را حدس بزنیم. :y X: مکان هواپیما مثال: مشاهده نقطه ( مجموعه نقاط کنارهم ) روی رادار - فرض کنیم می دانیم توزیع احتمال X به چه صورت است. حالت صفر: بدون مشاهده
تخمین با معیار مربع خطا: هدف: با مشاهده X Y را حدس بزنیم. :y X: مکان هواپیما مثال: مشاهده نقطه ( مجموعه نقاط کنارهم ) روی رادار - فرض کنیم می دانیم توزیع احتمال X به چه صورت است. حالت صفر: بدون مشاهده
:نتوين شور شور هدمع لکشم
 عددی آناليز جلسه چھارم حل معادلات غير خطي عمده روش نيوتن: مشکل f ( x را در f ( x و برای محاسبه ھر عضو دنباله باید ھر مرحله محاسبه کرد. در روشھای جایگزین تقریبی f ( x x + = x f جایگزین میکنم کنيم. ( x مشتق
عددی آناليز جلسه چھارم حل معادلات غير خطي عمده روش نيوتن: مشکل f ( x را در f ( x و برای محاسبه ھر عضو دنباله باید ھر مرحله محاسبه کرد. در روشھای جایگزین تقریبی f ( x x + = x f جایگزین میکنم کنيم. ( x مشتق
تلفات کل سيستم کاهش مي يابد. يکي ديگر از مزاياي اين روش بهبود پروفيل ولتاژ ضريب توان و پايداري سيستم مي باشد [-]. يکي ديگر از روش هاي کاهش تلفات سيستم
![تلفات کل سيستم کاهش مي يابد. يکي ديگر از مزاياي اين روش بهبود پروفيل ولتاژ ضريب توان و پايداري سيستم مي باشد [-]. يکي ديگر از روش هاي کاهش تلفات سيستم](/thumbs/87/95865628.jpg "تلفات کل سيستم کاهش مي يابد. يکي ديگر از مزاياي اين روش بهبود پروفيل ولتاژ ضريب توان و پايداري سيستم مي باشد [-]. يکي ديگر از روش هاي کاهش تلفات سيستم") اراي ه روشي براي کاهش تلفات در سيستم هاي توزيع بر مبناي تغيير محل تغذيه سيستم هاي توزيع احد کاظمي حيدر علي شايانفر حسن فشکي فراهاني سيد مهدي حسيني دانشگاه علم و صنعت ايران- دانشکده مهندسي برق چکيده براي
اراي ه روشي براي کاهش تلفات در سيستم هاي توزيع بر مبناي تغيير محل تغذيه سيستم هاي توزيع احد کاظمي حيدر علي شايانفر حسن فشکي فراهاني سيد مهدي حسيني دانشگاه علم و صنعت ايران- دانشکده مهندسي برق چکيده براي
آزمايشگاه ديناميك ماشين و ارتعاشات آزمايش چرخ طيار.
 ` آزمايشگاه ديناميك ماشين و ارتعاشات dynlab@jamilnia.ir www.jamilnia.ir/dynlab ١ تئوري آزمايش چرخ طيار يا چرخ ل نگ (flywheel) صفحه مدوري است كه به دليل جرم و ممان اينرسي زياد خود قابليت بالايي در ذخيرهسازي
` آزمايشگاه ديناميك ماشين و ارتعاشات dynlab@jamilnia.ir www.jamilnia.ir/dynlab ١ تئوري آزمايش چرخ طيار يا چرخ ل نگ (flywheel) صفحه مدوري است كه به دليل جرم و ممان اينرسي زياد خود قابليت بالايي در ذخيرهسازي
چكيده 1- مقدمه درخت مشهد ايران فيروزكوه ايران باشد [7]. 5th Iranian Conference on Machine Vision and Image Processing, November 4-6, 2008
![چكيده 1- مقدمه درخت مشهد ايران فيروزكوه ايران باشد [7]. 5th Iranian Conference on Machine Vision and Image Processing, November 4-6, 2008](/thumbs/75/72255428.jpg "چكيده 1- مقدمه درخت مشهد ايران فيروزكوه ايران باشد [7]. 5th Iranian Conference on Machine Vision and Image Processing, November 4-6, 2008") پنهاني سازي تصوير با استفاده از تابع آشوب و درخت جستجوي دودويي رسول عنايتي فر دانشكده مهندسي كامپيوتر دانشگاه آزاد اسلامي فيروزكوه ايران r.enayatifar@iaufb.ac.ir مرتضي صابري كمرپشتي دانشكده مهندسي كامپيوتر
پنهاني سازي تصوير با استفاده از تابع آشوب و درخت جستجوي دودويي رسول عنايتي فر دانشكده مهندسي كامپيوتر دانشگاه آزاد اسلامي فيروزكوه ايران r.enayatifar@iaufb.ac.ir مرتضي صابري كمرپشتي دانشكده مهندسي كامپيوتر
98-F-TRN-596. ترانسفورماتور بروش مونيتورينگ on-line بارگيري. Archive of SID چكيده 1) مقدمه يابد[
 مقدمه يابد[") و 98-F-TRN-596 محاسبه جهشهاي حرارتي و عمر از دست رفته ترانسفورماتور بروش مونيتورينگ n-line بارگيري آرش آقايي فر- حسين عزيزي موسسه تحقيقات ترانسفورماتور ايران واژه هاي كليدي: بارگيري ترانسفورماتور قدرت
و 98-F-TRN-596 محاسبه جهشهاي حرارتي و عمر از دست رفته ترانسفورماتور بروش مونيتورينگ n-line بارگيري آرش آقايي فر- حسين عزيزي موسسه تحقيقات ترانسفورماتور ايران واژه هاي كليدي: بارگيري ترانسفورماتور قدرت
Downloaded from ijpr.iut.ac.ir at 10:19 IRDT on Saturday July 14th پست الكترونيكي: چكيده ١. مقدمه
 مجلة پژوهش فيزيك ايران جلد ۱۳ شمارة ۳ پاييز ۱۳۹۲ Downloaded from ijpr.iut.ac.ir at 10:19 IRDT on Saturday July 14th 018 چكيده بهينه سازي مدل BCS براي سيستمهاي كوچك و محاسبة خواص ترموديناميكي هستههاي بخش
مجلة پژوهش فيزيك ايران جلد ۱۳ شمارة ۳ پاييز ۱۳۹۲ Downloaded from ijpr.iut.ac.ir at 10:19 IRDT on Saturday July 14th 018 چكيده بهينه سازي مدل BCS براي سيستمهاي كوچك و محاسبة خواص ترموديناميكي هستههاي بخش
3 و 2 و 1. مقدمه. Simultaneous كه EKF در عمل ناسازگار عمل كند.
 بررسي سازگاري تخمين در الگوريتم EKF-SLAM و پيشنهاد يك روش جديد با هدف رسيدن به سازگاري بيشتر فيلتر و كاستن هرينه محاسباتي امير حسين تمجيدي حميد رضا تقيراد نينا مرحمتي 3 و و گروه رباتيك ارس دپارتمان كنترل
بررسي سازگاري تخمين در الگوريتم EKF-SLAM و پيشنهاد يك روش جديد با هدف رسيدن به سازگاري بيشتر فيلتر و كاستن هرينه محاسباتي امير حسين تمجيدي حميد رضا تقيراد نينا مرحمتي 3 و و گروه رباتيك ارس دپارتمان كنترل
آزمایش 1: پاسخ فرکانسی تقویتکننده امیتر مشترك
 آزمایش : پاسخ فرکانسی تقویتکننده امیتر مشترك -- مقدمه هدف از این آزمایش بدست آوردن فرکانس قطع بالاي تقویتکننده امیتر مشترك بررسی عوامل تاثیرگذار و محدودکننده این پارامتر است. شکل - : مفهوم پهناي باند تقویت
آزمایش : پاسخ فرکانسی تقویتکننده امیتر مشترك -- مقدمه هدف از این آزمایش بدست آوردن فرکانس قطع بالاي تقویتکننده امیتر مشترك بررسی عوامل تاثیرگذار و محدودکننده این پارامتر است. شکل - : مفهوم پهناي باند تقویت
كند. P = Const. R به اين نكته توجه داشته باشيد كه گازها در
 كند hemodyamics قوانين بنيادي ترموديناميك براي درك نحوه عملكرد كمپرسور قانون گاز ايده ال است كه به شكل رابطه زير بيان مي شود: ν=r - به طوري كه: = فشار ν= حجم مخصوص = دماي مطلق = R ثابت گاز كه تابعي از
كند hemodyamics قوانين بنيادي ترموديناميك براي درك نحوه عملكرد كمپرسور قانون گاز ايده ال است كه به شكل رابطه زير بيان مي شود: ν=r - به طوري كه: = فشار ν= حجم مخصوص = دماي مطلق = R ثابت گاز كه تابعي از
5 TTGGGG 3 ميگردد ) شكل ).
 شكل ).") تكميل انتهاهاي مولكولهاي خطي DNA با توجه به اينكه RNA هاي پرايمر بايد از انتهاي مولكولهاي DNA برداشته شوند سي وال اين است در اين صورت انتهاي DNA هاي خطي چگونه تكميل ميگردد. در هنگام همانندسازي نه تنها
تكميل انتهاهاي مولكولهاي خطي DNA با توجه به اينكه RNA هاي پرايمر بايد از انتهاي مولكولهاي DNA برداشته شوند سي وال اين است در اين صورت انتهاي DNA هاي خطي چگونه تكميل ميگردد. در هنگام همانندسازي نه تنها
روش عملكردي استاندارد (SOP) AOBB95/SOP11/01. ا زمايش Rh(D) به روش لوله اي
 AOBB95/SOP11/01. ا زمايش Rh(D) به روش لوله اي") AOBB95/SOP11/01 روش عملكردي استاندارد (SOP) ا زمايش Rh(D) به روش لوله اي هدف/ اصول: 1) تعيين گروه Rh(D) گلبول قرمز خون بصورت فنوتيپ Rh-Positive و Rh-Negative با توجه به حضور و عدم حضور ا نتيژن D در سطح
AOBB95/SOP11/01 روش عملكردي استاندارد (SOP) ا زمايش Rh(D) به روش لوله اي هدف/ اصول: 1) تعيين گروه Rh(D) گلبول قرمز خون بصورت فنوتيپ Rh-Positive و Rh-Negative با توجه به حضور و عدم حضور ا نتيژن D در سطح
تحلیل مدار به روش جریان حلقه
 تحلیل مدار به روش جریان حلقه برای حل مدار به روش جریان حلقه باید مراحل زیر را طی کنیم: مرحله ی 1: مدار را تا حد امکان ساده می کنیم)مراقب باشید شاخه هایی را که ترکیب می کنید مورد سوال مسئله نباشد که در
تحلیل مدار به روش جریان حلقه برای حل مدار به روش جریان حلقه باید مراحل زیر را طی کنیم: مرحله ی 1: مدار را تا حد امکان ساده می کنیم)مراقب باشید شاخه هایی را که ترکیب می کنید مورد سوال مسئله نباشد که در
مفاهیم ولتاژ افت ولتاژ و اختالف پتانسیل
 مفاهیم ولتاژ افت ولتاژ و اختالف پتانسیل شما باید بعد از مطالعه ی این جزوه با مفاهیم ولتاژ افت ولتاژ و اختالف پتانسیل کامال آشنا شوید. VA R VB به نظر شما افت ولتاژ مقاومت R چیست جواب: به مقدار عددی V A
مفاهیم ولتاژ افت ولتاژ و اختالف پتانسیل شما باید بعد از مطالعه ی این جزوه با مفاهیم ولتاژ افت ولتاژ و اختالف پتانسیل کامال آشنا شوید. VA R VB به نظر شما افت ولتاژ مقاومت R چیست جواب: به مقدار عددی V A
ﺮﺑﺎﻫ -ﻥﺭﻮﺑ ﻪﺧﺮﭼ ﺯﺍ ﻩﺩﺎﻔﺘﺳﺍ ﺎﺑ ﻱﺭﻮﻠﺑ ﻪﻜﺒﺷ ﻱﮊﺮﻧﺍ ﻦﻴﻴﻌﺗ ﻪﺒـﺳﺎﺤﻣ ﺵﻭﺭ ﺩﺭﺍﺪﻧ ﺩﻮﺟﻭ ﻪ ﻱﺍ ﻜﺒﺷ ﻱﮊﺮﻧﺍ ﻱﺮﻴﮔ ﻩﺯﺍﺪﻧﺍ ﻱﺍﺮﺑ ﻲﻤﻴﻘﺘﺴﻣ ﻲﺑﺮﺠﺗ ﺵﻭﺭ ﹰﻻﻮﻤﻌﻣ ﻥﻮﭼ ﻱﺎ ﻩﺩ
 تعيين انرژي بلوري با استفاده از چرخه بورن - هابر چون معمولا روش تجربي مستقيمي براي اندازهگيري انرژي اي وجود ندارد روش محاسبه اين انرژي براي تركيبات يوني اهميت بسياري مييابد. اما مقداري انرژي اي با استفاده
تعيين انرژي بلوري با استفاده از چرخه بورن - هابر چون معمولا روش تجربي مستقيمي براي اندازهگيري انرژي اي وجود ندارد روش محاسبه اين انرژي براي تركيبات يوني اهميت بسياري مييابد. اما مقداري انرژي اي با استفاده
سعيدسيدطبايي. C=2pF T=5aS F=4THz R=2MΩ L=5nH l 2\µm S 4Hm 2 بنويسيد كنييد
 تمرينات درس اندازه گيري دانشگاه شاهد سعيدسيدطبايي تمرين سري 1 و 2 سوال 1: اندازه گيري را تعريف كرده مشخصات شاخص و دستگاه اندازه گيري را بنويسيد منظور از كاليبراسيون و تنظيم چيست. تفاوت دستگاههاي اندازه
تمرينات درس اندازه گيري دانشگاه شاهد سعيدسيدطبايي تمرين سري 1 و 2 سوال 1: اندازه گيري را تعريف كرده مشخصات شاخص و دستگاه اندازه گيري را بنويسيد منظور از كاليبراسيون و تنظيم چيست. تفاوت دستگاههاي اندازه
دانشکده ی علوم ریاضی جلسه ی ۵: چند مثال
 دانشکده ی علوم ریاضی احتمال و کاربردا ن ۴ اسفند ۹۲ جلسه ی : چند مثال مدر س: دکتر شهرام خزاي ی نگارنده: مهدی پاک طینت (تصحیح: قره داغی گیوه چی تفاق در این جلسه به بررسی و حل چند مثال از مطالب جلسات گذشته
دانشکده ی علوم ریاضی احتمال و کاربردا ن ۴ اسفند ۹۲ جلسه ی : چند مثال مدر س: دکتر شهرام خزاي ی نگارنده: مهدی پاک طینت (تصحیح: قره داغی گیوه چی تفاق در این جلسه به بررسی و حل چند مثال از مطالب جلسات گذشته
و دماي هواي ورودي T 20= o C باشد. طبق اطلاعات كاتالوگ 2.5kW است. در صورتي كه هوادهي دستگاه
 1- بخاري گازسوز كارگاهي مدل انرژي از تعدادي مجرا تشكيل شده كه گازهاي احتراق در آن جريان دارد و در اثر عبور هوا از روي سطح خارجي اين پره ها توسط يك پروانه محوري fan) (axial گرما به هوا منتقل مي شود. توان
1- بخاري گازسوز كارگاهي مدل انرژي از تعدادي مجرا تشكيل شده كه گازهاي احتراق در آن جريان دارد و در اثر عبور هوا از روي سطح خارجي اين پره ها توسط يك پروانه محوري fan) (axial گرما به هوا منتقل مي شود. توان
- 1 مقدمه كنند[ 1 ]:
![- 1 مقدمه كنند[ 1 ]:](/thumbs/89/99268476.jpg "- 1 مقدمه كنند[ 1 ]:") مكانيابي منابع توليد پراكنده در شبكه فوق توزيع با استفاده از الگوريتم ژنتيك غيرمسلط( NSGAII ) 2 1 ري وف قادري محمد رضا بسمي 1 دانشگاه شاهد دانشكده فني مهندسي Raof.ghaderi@yahoo.com 2 دانشگاه شاهد دانشكده
مكانيابي منابع توليد پراكنده در شبكه فوق توزيع با استفاده از الگوريتم ژنتيك غيرمسلط( NSGAII ) 2 1 ري وف قادري محمد رضا بسمي 1 دانشگاه شاهد دانشكده فني مهندسي Raof.ghaderi@yahoo.com 2 دانشگاه شاهد دانشكده
DA-SM02-1 هدف : 2- مقدمه
 DA-SM02 تست ضربه - هدف : تعيين مقدار انرژي شكست فلزات 2- مقدمه يكي از مساي ل مهم در صنعت كه باعث خسارات زيادي ميشود شكستن قطعات براثر تردي جنس آنها ميباشد. آزمايشهاي كشش و فشار با همه اهميت خود نميتوانند
DA-SM02 تست ضربه - هدف : تعيين مقدار انرژي شكست فلزات 2- مقدمه يكي از مساي ل مهم در صنعت كه باعث خسارات زيادي ميشود شكستن قطعات براثر تردي جنس آنها ميباشد. آزمايشهاي كشش و فشار با همه اهميت خود نميتوانند
Aerodynamic Design Algorithm of Liquid Injection Thrust Vector Control
 علوم و تحقيقات هوافضا جلد 2 شماره 2 بهار 1388 الگوريتم طراحي آيروديناميكي كنترل بردار تراست به روش پاشش مايع 2 1 مهدي هاشمآبادي و محمدرضا حيدري دانشگاه صنعتي مالك اشتر مجتمع دانشگاهي هوافضا مركز آموزشي
علوم و تحقيقات هوافضا جلد 2 شماره 2 بهار 1388 الگوريتم طراحي آيروديناميكي كنترل بردار تراست به روش پاشش مايع 2 1 مهدي هاشمآبادي و محمدرضا حيدري دانشگاه صنعتي مالك اشتر مجتمع دانشگاهي هوافضا مركز آموزشي
رياضي 1 و 2 تابع مثال: مثال: 2= ميباشد. R f. f:x Y Y=
 رياضي و رياضي و تابع تعريف تابع: متغير y را تابعي از متغير در حوزه تعريف D گويند اگر به ازاي هر از اين حوزه يا دامنه مقدار معيني براي متغير y متناظر باشد. يا براي هر ) y و ( و ) y و ( داشته باشيم ) (y
رياضي و رياضي و تابع تعريف تابع: متغير y را تابعي از متغير در حوزه تعريف D گويند اگر به ازاي هر از اين حوزه يا دامنه مقدار معيني براي متغير y متناظر باشد. يا براي هر ) y و ( و ) y و ( داشته باشيم ) (y
(POWER MOSFET) اهداف: اسيلوسكوپ ولوم ديود خازن سلف مقاومت مقاومت POWER MOSFET V(DC)/3A 12V (DC) ± DC/DC PWM Driver & Opto 100K IRF840
 اهداف: اسيلوسكوپ ولوم ديود خازن سلف مقاومت مقاومت POWER MOSFET V(DC)/3A 12V (DC) ± DC/DC PWM Driver & Opto 100K IRF840") منابع تغذيه متغير با مبدل DC به DC (POWER MOSFET) با ترانز يستور اهداف: ( بررسی Transistor) POWER MOSFET (Metal Oxide Semiconductor Field Effect براي كليد زني 2) بررسي مبدل DC به.DC كاهنده. 3) بررسي مبدل
منابع تغذيه متغير با مبدل DC به DC (POWER MOSFET) با ترانز يستور اهداف: ( بررسی Transistor) POWER MOSFET (Metal Oxide Semiconductor Field Effect براي كليد زني 2) بررسي مبدل DC به.DC كاهنده. 3) بررسي مبدل
قطعات DNA وصل ميشوند فاژT7. pppapcpc/a(pn) 1 2 فاژT4. pppapc (PN) 3. *** (p)ppa /G (PN) 7 pppa / G (Pn)~9 در حدود ۱۰
 1 2 فاژT4. pppapc (PN) 3. *** (p)ppa /G (PN) 7 pppa / G (Pn)~9 در حدود ۱۰") نواحي تكرشتهاي شده DNA به وسيله پروتي ينهايي كه به ا نها متصل ميشوند پايدار ميگردند نواحي تك رشتهاي كه در اثر فعاليت پروتي ينهاي هليكاز بوجود ميا يند ممكن است دوباره به يكديگر متصل شوند بنابراين نواحي
نواحي تكرشتهاي شده DNA به وسيله پروتي ينهايي كه به ا نها متصل ميشوند پايدار ميگردند نواحي تك رشتهاي كه در اثر فعاليت پروتي ينهاي هليكاز بوجود ميا يند ممكن است دوباره به يكديگر متصل شوند بنابراين نواحي
مثال( مساله الپالس در ناحیه داده شده را حل کنید. u(x,0)=f(x) f(x) حل: به کمک جداسازی متغیرها: ثابت = k. u(x,y)=x(x)y(y) X"Y=-XY" X" X" kx = 0
=f(x) f(x) حل: به کمک جداسازی متغیرها: ثابت = k. u(x,y)=x(x)y(y) XY=-XY X X kx = 0") مثال( مساله الپالس در ناحیه داده شده را حل کنید. (,)=() > > < π () حل: به کمک جداسازی متغیرها: + = (,)=X()Y() X"Y=-XY" X" = Y" ثابت = k X Y X" kx = { Y" + ky = X() =, X(π) = X" kx = { X() = X(π) = معادله
مثال( مساله الپالس در ناحیه داده شده را حل کنید. (,)=() > > < π () حل: به کمک جداسازی متغیرها: + = (,)=X()Y() X"Y=-XY" X" = Y" ثابت = k X Y X" kx = { Y" + ky = X() =, X(π) = X" kx = { X() = X(π) = معادله
آزمايش ارتعاشات آزاد و اجباري سيستم جرم و فنر و ميراگر
 ` آزمايشگاه ديناميك ماشين و ارتعاشات آزمايش ارتعاشات آزاد و اجباري سيستم جرم و فنر و ميراگر dynlab@jamilnia.ir www.jamilnia.ir/dynlab ١ تئوري آزمايش سيستمهاي ارتعاشي ميتوانند بر اثر تحريكات دروني يا بيروني
` آزمايشگاه ديناميك ماشين و ارتعاشات آزمايش ارتعاشات آزاد و اجباري سيستم جرم و فنر و ميراگر dynlab@jamilnia.ir www.jamilnia.ir/dynlab ١ تئوري آزمايش سيستمهاي ارتعاشي ميتوانند بر اثر تحريكات دروني يا بيروني
گروه رياضي دانشگاه صنعتي نوشيرواني بابل بابل ايران گروه رياضي دانشگاه صنعتي شاهرود شاهرود ايران
 و ۱ دسترسي در سايت http://jnrm.srbiau.ac.ir سال دوم شماره ششم تابستان ۱۳۹۵ شماره شاپا: ۱۶۸۲-۰۱۹۶ پژوهشهاي نوین در ریاضی دانشگاه آزاد اسلامی واحد علوم و تحقیقات دستهبندي درختها با عدد رومي بزرگ حسين عبدالهزاده
و ۱ دسترسي در سايت http://jnrm.srbiau.ac.ir سال دوم شماره ششم تابستان ۱۳۹۵ شماره شاپا: ۱۶۸۲-۰۱۹۶ پژوهشهاي نوین در ریاضی دانشگاه آزاد اسلامی واحد علوم و تحقیقات دستهبندي درختها با عدد رومي بزرگ حسين عبدالهزاده
يﺎﻫ ﻢﺘﻳرﻮﮕﻟا و ﺎﻫ ﺖﺧرد فاﺮﮔ ﻲﻤﺘﻳرﻮﮕﻟا ﻪﻳﺮﻈﻧ :سرد ﻲﺘﺸﻬﺑ ﺪﻴﻬﺷ هﺎﮕﺸﻧاد ﺮﺗﻮﻴﭙﻣﺎﻛ مﻮﻠﻋ هوﺮﮔ ﻪﻴﻟوا ﺞﻳﺎﺘﻧ و ﺎﻫﻒ ﻳﺮﻌﺗ
 BFS DFS : درخت یک گراف همبند بدون دور است. جنگل یک گراف بدون دور است. پس هر مولفه همبندی جنگل درخت است. هر راس درجه 1 در درخت را یک برگ مینامیم. یک درخت فراگیر از گراف G یک زیردرخت فراگیر از ان است که
BFS DFS : درخت یک گراف همبند بدون دور است. جنگل یک گراف بدون دور است. پس هر مولفه همبندی جنگل درخت است. هر راس درجه 1 در درخت را یک برگ مینامیم. یک درخت فراگیر از گراف G یک زیردرخت فراگیر از ان است که
t a a a = = f f e a a
 ا زمايشگاه ماشينه يا ۱ الکتريکي ا زمايش شمارهي ۴-۱ گزارش کار راهاندازي و تنظيم سرعت موتورهايي DC (شنت) استاد درياباد نگارش: اشکان نيوشا ۱۶ ا ذر ۱۳۸۷ ي م به نام خدا تي وري ا زمايش شنت است. در اين ا زمايش
ا زمايشگاه ماشينه يا ۱ الکتريکي ا زمايش شمارهي ۴-۱ گزارش کار راهاندازي و تنظيم سرعت موتورهايي DC (شنت) استاد درياباد نگارش: اشکان نيوشا ۱۶ ا ذر ۱۳۸۷ ي م به نام خدا تي وري ا زمايش شنت است. در اين ا زمايش
مربوطند. با قراردادن مقدار i در معادله (1) داريم. dq q
 داريم. dq q") مدارهاي تا بحال به مدارهايي پرداختيم كه در ا نها اجزاي مدار مقاومت بودند و در ا نها جريان با زمان تغيير نميكرد. در اينجا خازن را به عنوان يك عنصر مداري معرفي ميكنيم خازن ما را به مفهوم جريانهاي متغير با
مدارهاي تا بحال به مدارهايي پرداختيم كه در ا نها اجزاي مدار مقاومت بودند و در ا نها جريان با زمان تغيير نميكرد. در اينجا خازن را به عنوان يك عنصر مداري معرفي ميكنيم خازن ما را به مفهوم جريانهاي متغير با
مقاطع مخروطي 1. تعريف مقاطع مخروطي 2. دايره الف. تعريف و انواع معادله دايره ب. وضعيت خط و دايره پ. وضعيت دو دايره ت. وتر مشترك دو دايره
 مقاطع مخروطي فصل در اين فصل ميخوانيم:. تعريف مقاطع مخروطي. دايره الف. تعريف و انواع معادله دايره ب. وضعيت خط و دايره پ. وضعيت دو دايره ت. وتر مشترك دو دايره ث. طول مماس و طول وتر مينيمم ج. دورترين و نزديكترين
مقاطع مخروطي فصل در اين فصل ميخوانيم:. تعريف مقاطع مخروطي. دايره الف. تعريف و انواع معادله دايره ب. وضعيت خط و دايره پ. وضعيت دو دايره ت. وتر مشترك دو دايره ث. طول مماس و طول وتر مينيمم ج. دورترين و نزديكترين
در کدام قس مت از مسیر انرژی جنبشی دستگاه بیشینه و انرژی پتانسیل گرانشی آن کمینه است
 در کدام قس مت از مسیر انرژی جنبشی دستگاه بیشینه و انرژی پتانسیل گرانشی آن کمینه است فيزيك سیمای فصل -5 كار -5 كار و انرژي جنبشي 3-5 پايستگي انرژي مكانيكي 4-5 توان پرسشهاي مفهومي مسئلهها 86 فصل پنجم/کار
در کدام قس مت از مسیر انرژی جنبشی دستگاه بیشینه و انرژی پتانسیل گرانشی آن کمینه است فيزيك سیمای فصل -5 كار -5 كار و انرژي جنبشي 3-5 پايستگي انرژي مكانيكي 4-5 توان پرسشهاي مفهومي مسئلهها 86 فصل پنجم/کار
HMI SERVO STEPPER INVERTER
 راهنماي راهاندازي سريع درايوهاي مخصوص ا سانسور كينكو (سري (FV109 سري درايوهاي FV109 كينكو درايوهاي مخصوص ا سانسور كينكو ميباشد كه با توجه به نيازمنديهاي اساسي مورد نياز در ايران به بازار عرضه شدهاند. به
راهنماي راهاندازي سريع درايوهاي مخصوص ا سانسور كينكو (سري (FV109 سري درايوهاي FV109 كينكو درايوهاي مخصوص ا سانسور كينكو ميباشد كه با توجه به نيازمنديهاي اساسي مورد نياز در ايران به بازار عرضه شدهاند. به
مقدمه دسته بندي دوم روش هاي عددي دامنه محدود اهداف: هاي چندجمله اي رهيافت هاي محاسباتي: سعي و خطا دامنه نامحدود
 اهداف: محاسبه ريشه دستگاه دسته عدم وابسته معادالت ريشه هاي چندجمله اي معادالت غيرخطي بندي وابستگي به روش به مشتق مشتق تابع مقدمه غير خطي هاي عددي تابع دسته بندي دوم روش هاي عددي دامنه محدود دامنه نامحدود
اهداف: محاسبه ريشه دستگاه دسته عدم وابسته معادالت ريشه هاي چندجمله اي معادالت غيرخطي بندي وابستگي به روش به مشتق مشتق تابع مقدمه غير خطي هاي عددي تابع دسته بندي دوم روش هاي عددي دامنه محدود دامنه نامحدود
بسم اهلل الرحمن الرحیم آزمایشگاه فیزیک )2( shimiomd
2( shimiomd") بسم اهلل الرحمن الرحیم آزمایشگاه فیزیک )( shimiomd خواندن مقاومت ها. بررسی قانون اهم برای مدارهای متوالی. 3. بررسی قانون اهم برای مدارهای موازی بدست آوردن مقاومت مجهول توسط پل وتسون 4. بدست آوردن مقاومت
بسم اهلل الرحمن الرحیم آزمایشگاه فیزیک )( shimiomd خواندن مقاومت ها. بررسی قانون اهم برای مدارهای متوالی. 3. بررسی قانون اهم برای مدارهای موازی بدست آوردن مقاومت مجهول توسط پل وتسون 4. بدست آوردن مقاومت
بررسي روايي و پايايي در پژوهش
 دانشگاه علوم پزشکی و خدمات درمانی تبریز مرکز کشوری مدیریت سالمت )NPMC( عنوان دوره: بررسي روايي و پايايي در پژوهش گردآورنده: محمد تقي خداياری پايیز 9316 عنوان دوره: بررسی روایی و پایایی در پژوهش اهداف درسی
دانشگاه علوم پزشکی و خدمات درمانی تبریز مرکز کشوری مدیریت سالمت )NPMC( عنوان دوره: بررسي روايي و پايايي در پژوهش گردآورنده: محمد تقي خداياری پايیز 9316 عنوان دوره: بررسی روایی و پایایی در پژوهش اهداف درسی
آموزش SPSS مقدماتی و پیشرفته مدیریت آمار و فناوری اطالعات -
 آموزش SPSS مقدماتی و پیشرفته تهیه و تنظیم: فرزانه صانعی مدیریت آمار و فناوری اطالعات - مهرماه 96 بخش سوم: مراحل تحلیل آماری تحلیل داده ها به روش پارامتری بررسی نرمال بودن توزیع داده ها قضیه حد مرکزی جدول
آموزش SPSS مقدماتی و پیشرفته تهیه و تنظیم: فرزانه صانعی مدیریت آمار و فناوری اطالعات - مهرماه 96 بخش سوم: مراحل تحلیل آماری تحلیل داده ها به روش پارامتری بررسی نرمال بودن توزیع داده ها قضیه حد مرکزی جدول
فصل دهم: همبستگی و رگرسیون
 فصل دهم: همبستگی و رگرسیون مطالب این فصل: )r ( کوواریانس ضریب همبستگی رگرسیون ضریب تعیین یا ضریب تشخیص خطای معیار برآور ( )S XY انواع ضرایب همبستگی برای بررسی رابطه بین متغیرهای کمی و کیفی 8 در بسیاری
فصل دهم: همبستگی و رگرسیون مطالب این فصل: )r ( کوواریانس ضریب همبستگی رگرسیون ضریب تعیین یا ضریب تشخیص خطای معیار برآور ( )S XY انواع ضرایب همبستگی برای بررسی رابطه بین متغیرهای کمی و کیفی 8 در بسیاری
نگرش دانشجويان رشته بهداشت و ايمني مواد غذايي نسبت به رشته تحصيلي و آينده شغلي خود در دانشگاه هاي علوم پزشكي كشور
 مجله دانشكده بهداشت و انستيتوتحقيقات بهداشتي زمستان ١٣٩٦ دوره ١٥ شماره مقاله پژوهشي چهارم صفحه ٣٢٤-٣١٥ نگرش دانشجويان رشته بهداشت و ايمني مواد غذايي نسبت به رشته تحصيلي و آينده شغلي خود در دانشگاه هاي
مجله دانشكده بهداشت و انستيتوتحقيقات بهداشتي زمستان ١٣٩٦ دوره ١٥ شماره مقاله پژوهشي چهارم صفحه ٣٢٤-٣١٥ نگرش دانشجويان رشته بهداشت و ايمني مواد غذايي نسبت به رشته تحصيلي و آينده شغلي خود در دانشگاه هاي